
LLM councils show groupthink
perils and problems of LLM peer review

One way to get the best out of LLMs is to use model diversity. The models are not all the same so if you use their unique natures, you can get better responses. We saw it with the work on MarketBench. And we also saw this when Karpathy came up with LLM Council as a way to get multiple models to work with each other and get us a better answer.
But I started wondering, with people, when you put a bunch of them together in a committee, some things get better but some things do get worse! And relying on an LLM to audit is also error-prone. “Design by committee” is a four letter word for a reason. LLMs are better than us probably, but surely this process is also somewhat lossy. So what do we lose?
To test it, I set up an experiment, where I set up a few committees of models:
First, I took each answer, then gave those to a fourth model and asked it to write the final version.
Then, the llm-council – essentially peer review and then a chairperson summarises
And a “best answer” picker – just a direct pick.
With people, the problem with committees is that they “smooth out” all idiosyncrasies. They take out any “spiky” points of view, and make things much more normie. Same thing here. So to test how we do I had to find some way to grade how the various final responses were. So I broke each answer into small “cards” using Sonnet. A card could be a mechanism, observation, metric, failure mode, image, or some other important detail.
Then I clustered cards that appeared to mean the same thing. If a cluster appeared in one solo answer, we called it a single-model idea. If it appeared in more than one, its shared. And two judges scored the solo-derived clusters without knowing which model produced them or whether a council kept them.
Now it’s not perfect, but it’s the cleanest way to test the problem of “how to rate which answer is better” that I could find without doing human rating.
First, the result: the council does not simply keep the best bits from everyone. It keeps a minority of the good ideas, while peer review seems to give consensus ideas an extra push.
Now, obviously the final summarized versions usually read better. It is calmer, more complete, less jagged, all things you’d expect. But we had misses. Examples.
A field report noticing that salvaged retail scent cartridges had become status symbols in a squatted mall, used to mask the smell of communal living.
An incident report arguing that logged-but-deprioritized risks are more dangerous than unknown ones, because they manufacture a false sense of control.
A data-recovery plan that asks users to re-confirm suspect fields at their next login (”please re-confirm your shipping address”), quietly crowdsourcing recovery from the one authoritative source.
In the final runs, the blended council kept only about a quarter of the good ideas that appeared in just one model’s answer. Remember, these were ideas that two blind judges rated as useful, non-obvious, and worth keeping, and still roughly three quarters did not make it into the final answer.
The peer-review version did not solve this either. The rare ideas survived at about the same rate as in plain blending: 24% versus 22%. But if several models had raised the same idea, the peer-review council kept it about a third of the time, but if only one model raised it, a quarter.
To test this, I ran sixteen open-ended prompts: eight strategy problems and eight writing tasks.
Figure 1. The experiment path from solo answers to idea coverage.
I plotted what happened with the ideas. The red dot below is good idea that only one model came up with. Blue is good ideas that multiple models came up with. And the X-axis shows how many of each actually showed up in the final answer. So the selector for instance showed about 37% of all good single-model ideas, and 24% of the multiple-models ideas, which makes sense because it picks one full answer and discards the others.
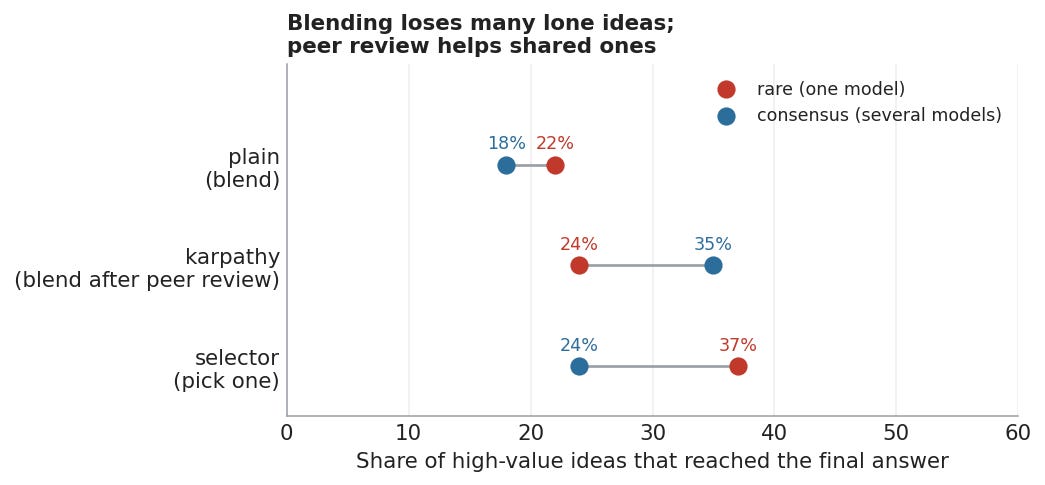
Figure 2. Coverage of blind-rated high-value ideas.
The consensus tilt is smaller here, but interesting. In the peer-review council, shared high-value ideas survived had a 11% uplift over single-model high-value ideas. Or put another way, a 50% relative lift!
The denominator for shared ideas is small though. What’s interesting is that this shows us how the specific topology of the “council” changes what you’re likely to get, like a peer-review round ends up becoming a consensus detector even above a single model blending the answers from all other models.
This is a problem with all cognitive beings. In group decision-making research, back in the 1980s, Stasser and Titus called it biased sampling of shared information - groups are more likely to discuss information that several members already know than information only one has. That line of work led to the “hidden profile” problem, where a group can miss the best answer because the crucial evidence is scattered across individuals rather than shared up front. We’re seeing the same thing here.
The work on LLMs meanwhile so far have mostly come from the other direction. Multi-agent debate papers ask whether multiple models can improve the final answer, and yes, they often can! But depending on the topic and the question, a council can absolutely improve the average answer and still drop some of the best ideas.
As users, we want to get better answers, cheaply. That’s the whole goal. Councils are great ways to make some answers better depending on how you structure it. But they’re not cheaper. So, it is important to make sure they are, actually, better! If they’re not, or at least not universally, then how the council should be structured is an incredibly important problem!
What we still see here is that there is no free token lunch. If you use councils to get the benefits of model diversity, don’t assume it will preserve the best ideas. To do that we have to work harder, and understand how to work with these models.
For instance, one thing we know is that the best way with LLMs usually is to be explicit, since otherwise even if they’re aligned they cause emergent problems. So the best protocol might be to explicitly gather and store the best ideas from each solution separately and ensure they’re stored, ranked and assessed, before a final answer is written and revised.

It does much better, though it’s slower and heavier. I don’t know if this is the best we can do though. The structure might change depending on the question asked, the domain, or the types of answer expected.
Humans have gone through thousands of types of “councils” until we reached interim solutions which give us decent results nowadays. And even then, we have to change the shape of the councils constantly, as we evolve, and society evolves.
To figure out how to get the best results from our work requires a lot more effort into designing the councils. If you’re working with them, you will need to experiment and eval against your individual problem sets, which is the only way to know if this specific council setup will help with your specific problem. Copying someone else’s homework won’t work!
Homo Agenticus are odd enough creatures that using them well requires much much more experimentation than one might assume. Especially when the problems of using them suboptimally is that we lose actual functionality, often without knowing it!
Very interesting. I've had a draft about something similar to this brewing for a while and I keep experimenting with this. Maybe I'll finish the writeup at some point, but yours is good! 💚 🥃
This seems like the outcome I would expect. Still sounds better than a human committee. The problem in my experience is not that committees smooth things out. They issue ragbag reports which try to force incompatible ideas into the same frame and turn out to be unworkable and solve nothing.