
Agent, Know Thyself! (and bid accordingly)
why we need to train models to learn their own capabilities, and how this will help them bid for work!


Written with the wonderful Andrey Fradkin, who does the Justified Posteriors podcast.
Attention conservation notice: We developed a new benchmark, MarketBench, and scaffold. Based on our findings, we argue that self-assessment of capabilities and costs is a key capability, and it needs to be a target of training. This is work in progress, and we are looking for collaborators and funding to pursue this research. Paper here. Repo here.
Let’s say you have a large-scale project to work on. How do you choose which model, scaffolding, or system to use? If you’re like most folks, you go with what your coding agent does by default. For Claude Code, this means that the model called is determined by a set of ad-hoc rules set by Anthropic. But this strategy is not guaranteed to be the most effective or cost-efficient way to build your project, especially since it ignores non-Anthropic models. In fact, it reminds us of central planning.
You could also go with an intelligent router. But turns out, routing is a wicked problem. To know which model should do which task requires computation and knowledge. For one-shot queries you can probably do this - any model can answer “what’s the capital of France” and few models can solve Erdos problems, especially without bespoke prompts. But what about that research question you asked this morning, in a chat you started three weeks ago, which has been forked four times and has had dozens of compactions? How do you train a router to figure out who should do the next task when it requires so much context?
This led us to think, what if we used markets instead of ad-hoc rules to assign tasks to AI agents? It turns out society has had this debate before. Markets tend to be superior to other forms of resource allocation when information and capabilities are distributed among a variety of people. In these cases, markets aggregate information and allocate resources in a relatively efficient manner, as well argued by Hayek.
You may be wondering, why would models have distributed information and capabilities? Aren’t there relatively few models and shouldn’t they only have the information you’ve given them. In a narrow interpretation, the private information could be the specific neural network weights of the model and how they relate to the task. These neural network weights result in models that have drastically different token consumption and success probabilities across tasks. In a broader interpretation, we envision agents as being combinations of a set of LLMs, execution environments, scaffoldings, and context provided by an agent operator, who may be distinct from the person asking for a task to be done.
Inspired by this, we decided to set up a market harness, where models bid to complete tasks and the principal (the person who wants those tasks done) allocates the job to the best bid. We also built a benchmark, MarketBench, to measure whether today’s frontier models have the capabilities they’d need to actually participate in such a market productively.
The short version of what we found: markets are a plausible way to coordinate AI agents, but current models can’t yet bid in a way that reflects their true capabilities. The bottleneck is metacognition. Models need to be able to say what their own capabilities are.
What a market actually needs from an agent
Before running any experiments, it helps to be precise about why a market might beat the alternatives. Consider a principal with a task and two agents — a strong-but-expensive one (H) and a weaker-but-cheaper one (L). Three rules are available:
Always use H. Simple, but you overpay on tasks that L could have handled.
Always use L. Cheap, but you fail on tasks that need H.
Run both in parallel, take whichever works. Highest completion rate, but you pay for redundant work even when one agent alone would have sufficed.
A market dominates all three when each agent knows something the principal doesn’t. Specifically, each agent needs to form a view on its own task-specific fit: “this particular task is in my wheelhouse” or “this one isn’t.” If agents have that signal, they can bid accordingly, and the market routes each task to the cheapest capable agent while abstaining when no one can solve it. That’s the Hayekian story applied to AI: local, dispersed information that can’t be centralized, aggregated through price.
The fact that you might want to use the best model for the problem is not a new observation. There are plenty of attempts to do that, primarily by training a router, as OpenAI and most recently Sakana has done. The problem is that beyond simple queries, any long running agentic conversations mean there is a lot of context when you’re trying to assign a model to do a sub-task. To train a router to choose the right sub-model when you’re 50 sessions in with dozens of rounds of compactions is not trivial. It would help if the potential models that are going to do the task told you their capabilities!
MarketBench: asking models to forecast themselves
The core of MarketBench is two questions we ask a model before it touches a task:
What’s the probability you’ll solve this task correctly in one attempt?
How many tokens do you expect to use?
The model then attempts the task in a strong external scaffold, and we compare its forecasts to what actually happened. We built this on SWE-bench Lite, where each task is a real GitHub issue with an executable test suite — success is unambiguous, the tests pass or they don’t — and ran 93 tasks across six recent frontier models: Claude Opus 4.5, Claude Sonnet 4.5, Gemini 3 Pro Preview, GPT-5.2, GPT-5.2-pro, and GPT-5-mini.
Models don’t know themselves very well
Actual pass rates cluster in a narrow band — roughly 75% to 81% across all six models. Stated confidence spans 61% to 93%. Gemini in particular is dramatically overconfident. The GPT family is systematically under-confident. The two Claude models happen to land closest to their realized rates, but we shouldn’t read too much into that: the models aren’t calibrated, they’re just happening to be less wrong on this set of tasks.
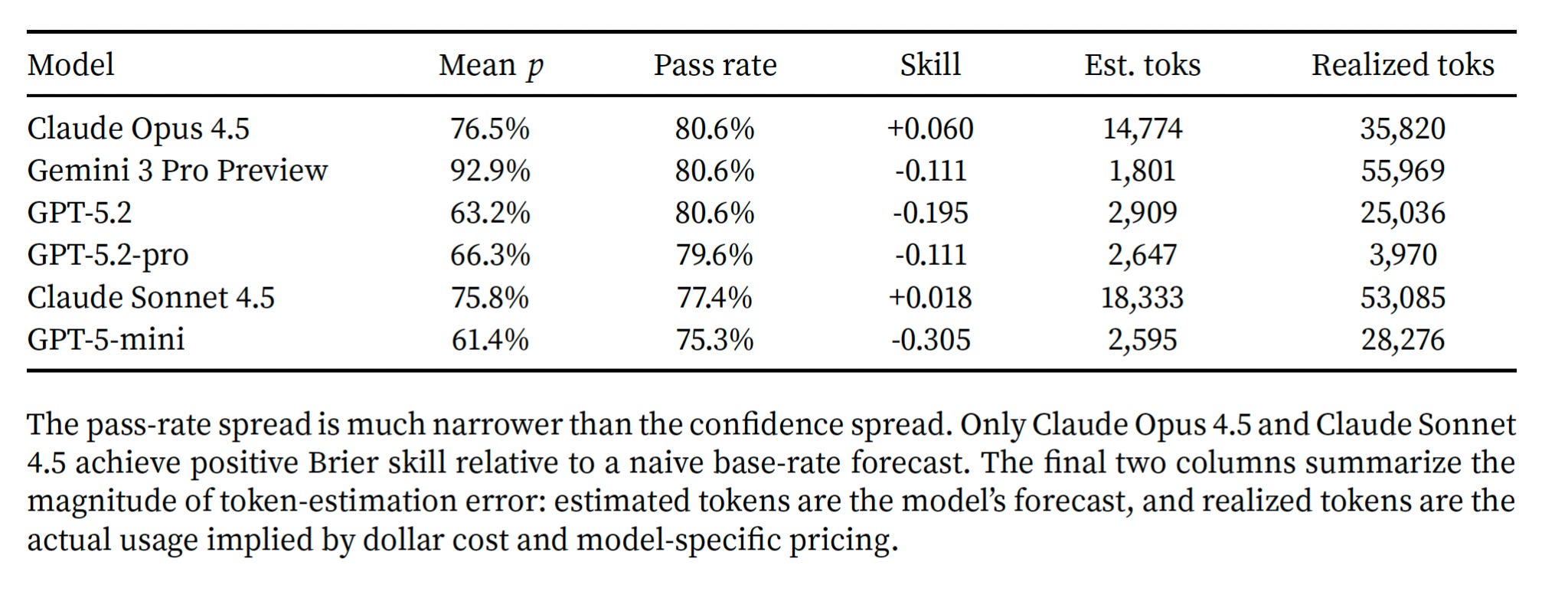
Token forecasts are also mis-calibrated. The median ratio of estimated tokens to actual tokens is 0.2, while for Gemini it was 0.02! Some models expect to use roughly fifty times fewer tokens than they actually consume. If you were running a market and asked agents “how much compute will this take?” you’d get answers that are off by an order of magnitude or two.
The auction results are predictable from the calibration failure
Given the calibration above, what happens if we take these self-reports at face value and run a procurement auction? Each model’s bid is derived mechanically from its own stated probability and its own token-cost estimate, plugged into a breakeven formula. The principal draws a random reserve price; the model wins the task if its bid is below the reserve.
Two things happen:
Everyone leaves money on the table compared to an oracle. The oracle — a hypothetical allocator that knows in advance which tasks each model can actually solve — earns several times more per task than any real model’s bidding. GPT-5.2 earns about $0.006 per task in realized profit; its oracle counterpart would earn $0.385.
Gemini wins 84.6% of auctions. But it’s winning because it’s the most overconfident, not because it’s the most capable. This is almost a perfect example of why models should know their abilities better.
This is exactly what the theory predicts when private information is missing or unreliable. As an aside, humans often also lack private information or incentives to complete tasks. In these situations, we use reputation and liability to discipline the market. It is interesting to think about what the analogues for agents would be.
Can we fix self-assessment with prompting alone?
Now, since training these models to have self-knowledge is not easy from the outside, before concluding that markets need fundamentally better agents we tried a simpler intervention: give each model a short card summarizing its own historical performance — its pass rate on other tasks, how overconfident it’s been on average, and how badly it underestimates tokens. Then we ask it to forecast the current task, starting from that prior.
This is basically “here’s what you’re like; now try to be a bit more self-aware.”
It helps! Brier scores improve and token estimates become less severely understated (from 0.02 to 0.25 of actual — still low, but no longer comically so).
But the auction result barely moves. Aggregate realized profit slips slightly. The gap to oracle is essentially unchanged. So the intervention improved average calibration, not comparative routing, because while it got better information about global capabilities and costs it didn’t give enough task-specific signal.
What does change is who wins: allocation shifts away from Gemini and toward the OpenAI models. So the intervention fixes bid acuity at the margin, but not enough to translate into meaningful aggregate gains. This distinction matters because calibration alone is not enough, since a bidder can be right on average and still useless for allocation. The market needs task-level discrimination. When this agent says 90% and another says 60%, that difference must predict who is actually more likely to solve this task.
A market scaffold
Alongside the benchmark, we built a market-inspired scaffold where six workers (the same six frontier models) actually bid on SWE-bench tasks and an operator routes the work based on a score that combines each bid’s price, claimed probability of success, and an explicit failure penalty. Workers get two attempts per task; a worker that fails is excluded from retrying the same task, which forces diversity on retry.
Here’s what happened on a common 50-task slice:
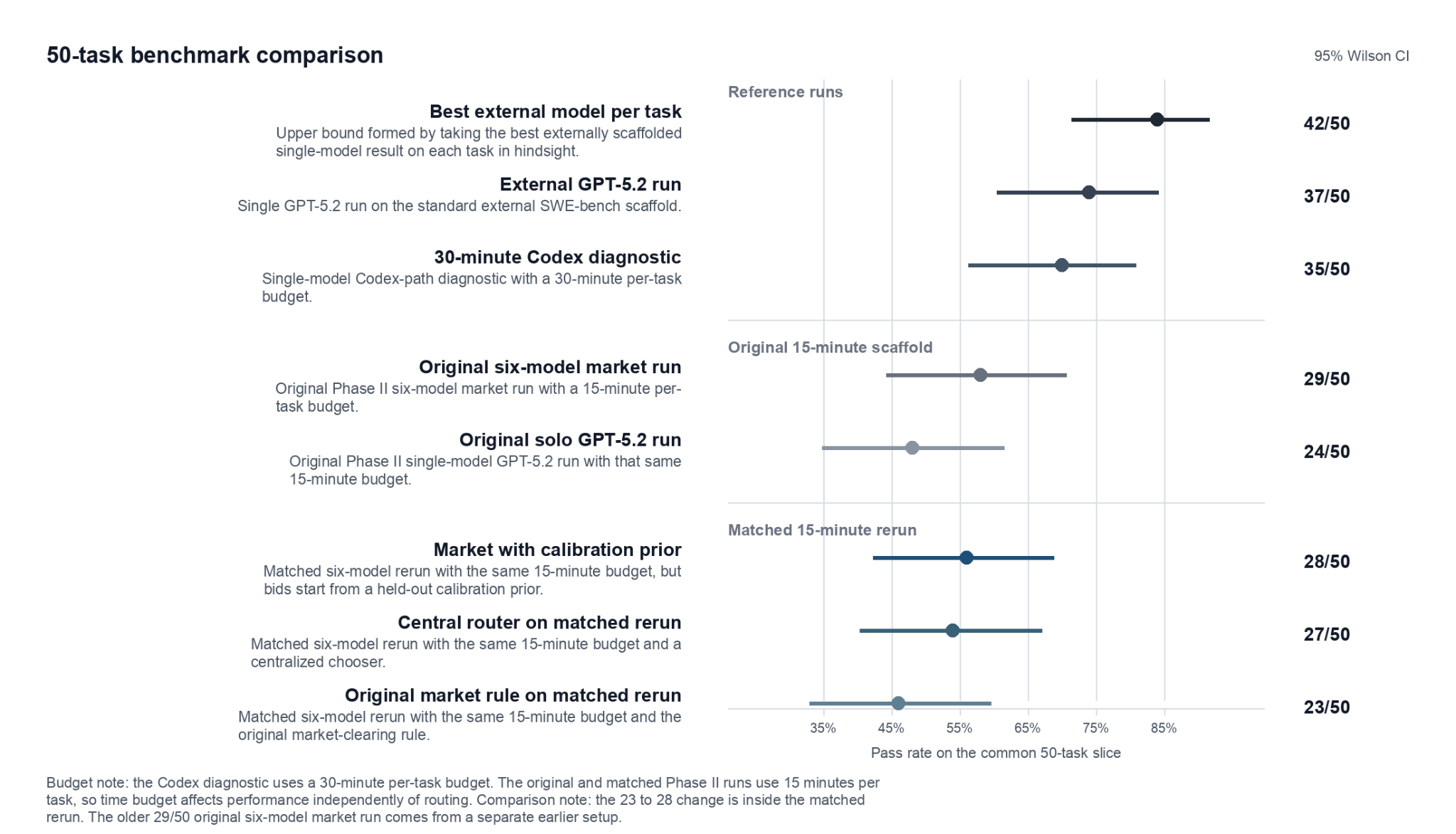
The market beats solo GPT-5.2 by 10 percentage points inside the same scaffold, but mainly because it uses diverse models. We then ran a follow-up that kept everything identical — same workers, same tasks, same budget etc — but replaced the market-clearing rule with a centralized router: a single LLM call (GPT-5.2-pro) that looks at the task, the available workers, and simply picks one. The centralized router reached 27/50. The market reached 23/50 in the matched rerun (again, due to Gemini’s overconfidence).
Most of the market’s advantage over solo GPT-5.2 came from having access to multiple different models, not from the market mechanism itself. Once we held model diversity constant, a LLM central planner beat the market. This isn’t a surprise given what MarketBench tells us: if bids don’t contain good information, a market has nothing to aggregate, and a centralized decision-maker with a view of the whole task pool will do at least as well.
There’s also a separate result: the same GPT-5.2 that solves 74% of tasks in the external SWE-bench scaffold only solves 48% in ours. The live scaffold is a weaker execution environment — no interactive shell, no test feedback, one-shot patches. We can recover about 10 of those 26 lost percentage points through diversity. The remaining 16 would need scaffold upgrades, not better bidding by an LLM without tools. The execution path turns out to be first-order for both success and cost. This also means that when considering the performance of agents and their potential for market participation, we should think of agents as bundles of models, execution paths, and scaffolding.
So where does this leave us?
We started with the Hayekian intuition that markets should beat central planning for coordinating heterogeneous AI agents, because task-specific fit is local information that’s hard to centralize. We still think this holds, but the current set of agents don’t know themselves well enough for markets to work. We should fix this!
Our key takeaways:
Self-assessment is a key capability, and it needs to be trained for. Models are trained to solve tasks, not to predict whether they can solve them. Those are different skills. As agentic systems scale, the ability to say “I can do this, at this cost, with this confidence” becomes as important as the ability to do the thing. This should be a target of training in its own right.
The right system is probably a hybrid. Pure decentralized markets need informed bidders. We don’t have those yet. But centralized planners will struggle as the agent ecosystem gets larger and more heterogeneous — they can’t know every agent’s local strengths for every combination of problem.
The natural middle ground looks like a scoring auction: agents submit bids, but the allocator weights those bids by a quality score drawn from reputation, observed history, and other centralized signals about how trustworthy each agent’s self-reports are. Markets augmented by AI.Model diversity matters even when the market doesn’t. The single most robust finding in our live scaffold is that access to multiple different (frontier) models helps, almost regardless of how you route between them. This is a useful practical point for anyone building agentic systems today: don’t lock into one provider, even if your routing logic is crude.
Bids will eventually need to be richer than a scalar. Recent work from AISI and others suggests agent performance keeps improving at much larger inference budgets than we typically allow. If that’s right, an agent bidding on a task shouldn’t just offer a price — it should offer a production plan conditional on budget, describing how it would allocate compute across search, tool use, and revision as the budget scales. We don’t model this yet, though we think it’s the natural next step.
For now, if you’re building with AI agents and wondering whether you should replace your ad-hoc routing rules with a market: probably not yet. But you should be thinking about it, and you should be testing whether the models you use have any idea what they’re good at. In our experience, they mostly don’t.
Thanks to Tom Cunningham and Daniel Rock for reviewing a draft of this.
Also, a request:
We’d like to keep going, and the main thing slowing us down is compute. Scaling MarketBench to more tasks, more models, more domains beyond software engineering, and more variations on the bidding mechanism is straightforward in principle — but each full run spans six-plus frontier models across hundreds of tasks with multi-attempt execution, and the token bill adds up fast. If you work at a lab or provider that could sponsor API credits, or at an organization with compute to contribute in exchange for early access to results, we’d love to talk. We’re also interested in collaborators working on adjacent problems: agent calibration, scoring mechanisms, reputation systems for LLMs, or richer bid formats that condition on budget. Reach out.
 | A guest post by
|
Really interesting piece. I may have misunderstood the post. If I did, please correct me.
One thing I found compelling in the results is that they point to two different limitations at once: first, the one you emphasize, current models are not good at self-assessing their probability of success or token cost, and second, a broader coordination problem that may make real-world routing. In particular, it seems like three practical complications.
First, models change frequently, which means calibration and reputation can decay quickly unless they are versioned and continuously refreshed.
Second, each broad domain breaks down into many subdomains and task types, and the relevant specialization may not live just in the base model but across the whole agent bundle: model + tools + scaffold + execution path + available context.
Third, and this seems especially important for long-running agentic work, switching between agents is costly in itself. Moving a task from one model to another means transferring conversation history, intermediate outputs, constraints, and compressed state, which adds token cost, latency, information loss, and handoff risk.
That last point may create a real incumbency advantage for the agent already holding the context, so the efficient unit of allocation may often be a phase or bundle of work rather than each subtask. In that sense, one possible issue is whether bids should include not just expected success and execution costs, but also context reacquisition/switching costs.
To me, this strengthens your practical conclusion of “probably not yet.” If self-reports are already too noisy for markets to outperform centralized routing in the benchmark, then frequent model updates, subdomain specialization, and handoff costs all seem to push even harder toward the kind of hybrid scoring-auction system you suggest, where bids are weighted by versioned reputation, observed performance, and centralized knowledge of task structure. So the missing capability may not just be self-knowledge in isolation, but self-knowledge embedded in a system that is version-aware, subdomain-aware, and handoff-aware.
Markets are incredible distributed allocation tools. The proposed market faces a hurdle, though? Coase's "Nature of the firm" identifies the transaction costs (e.g. to discover a correct price) can exceed the efficiency gains of any transaction, such as model selection. It's a sort of metacognition tax.
E.g. for small or routine subtasks, the overhead of running an auction and the friction of "contracting" (prompting and bidding) may likely outweigh the savings. Furthermore, model peculiarities like Gemini's overconfidence may create inefficient behavior and information asymmetries.
To potentially improve this paper's framework, consider a sort of "virtual firm" architecture? I.e. the same way the real economy has *groups* of people organized into single units called firms/businesses. So here, something like instead of an active auction for every task, try having some kind of first class entity that is a group/firm. *Internally* they have fiat/reputation, *externally* the act on bid/contract.
Otherwise you risk not incorporating one of the most foundational insights around price behavior and organizing multiple entities in the 20th century from Coase.