
State of the Canon
Onwards


The state of the Canon is strong. Strange Loop Canon is startlingly close to 500k words over 167 essays, something I knew would probably happen when I started writing three years ago, in a strictly mathematical sense, but like coming closer to Mount Fuji and seeing it rise up above the clouds, it’s pretty spectacular.
So, first of all, I love you guys! We’re just shy of 10k readers here, not counting RSS folks, so if you can bring some awesome folks over to the Canon I’d appreciate it!
Something else I grokked as I was writing this, belatedly perhaps, is that I am obsessive. It’s the only way I have been able to do anything. I must have had an inkling because one of my promises to myself when I started writing was that I would not look at any metrics associated with writing. Clearly this was the right choice, but it is interesting now that we’ve got some data to notice some patterns on the topics that recur and the motifs that repeat.
For instance, there is an entire subculture of essays that revolve around the various layers and meta-layers of technology, finance and culture, and I think we’re squarely in the middle of that Bermuda triangle. But even within those I played a lot of glass bead games this year. Looking ahead I feel we’re reaching the limits of that, and feel 2024 is the year where more wonkiness is likely to emerge.
And there’s so much more to read and write about! Talk about living in post scarcity society. I’ve barely done any book reviews this year, even though I read a lot. Or movies for that matter. Or travel. Or deep dives into companies or technologies or economies, including a “What Is Money” series I promised someone.
Anyhow as they say the past is prologue and future’s our discharge, but for now back to the state of the canon. The big part of the year was both on the breadth of essays and topics, but also the depth with one in particular, no prizes for guessing, which ended with me starting an essay and writing a book. That’s also how I ended up writing Building God this year. But more about that later.

First, let’s start with just two of the essays that struck a chord. One was Rest. I wrote this because I was on a sabbatical and I found it to be an incredibly underexplored and underdiscussed topic. And it seemed like an iceberg, with plenty interesting on the surface but with such a diverse group of people having experience with it, first-hand and second, with plenty of thoughts and opinions and questions.
Rest

Picture a young Albert Einstein working as a patent clerk in 1905. He has a steady job, but his mind remains restless, filled with ideas that clash with the rigid conventions of physics. During the day, he mechanically processes patent applications. But away fro…
There’s a lot more I want to say on this topic, not least because another project I’ve had has been on reading and analysing people who did extraordinary things in the past, and a disproportionate number of them had “gaps” in what you might consider their daily lives or routines or careers, which spurred them to even greater heights. There’s a treasure trove of what I’ve identified here, and this will be sure to come up.
This, by the way, was also how I ended up reading a ton of books the last year, because turns out rabbitholes of curiosity lead to wonderful warrens of discovery.
The other big topic for me was the good old one of Innovation. I took a data-backed look at how innovations came about all throughout human history.
Innovation

I, Fax Machine Before the internet, and the telephone, was the fax. Before instantaneous global communication news took days or even weeks to travel from one city to another. Into this world the fax arrived like a meteor, revolutionising the very essence of how we connect. But among its many versions, the printing telegraph stands out, weaving together t…
This was a very long time coming, because I’ve been creating a database of all human innovations since we became a species as another project. It’s also the most effort that’s gone into one of my essays, because even to start to write it I had to get a list of about 1700+ innovations (as of last count), and read about each one and categorise them, and then try and analyse what it told me that hadn’t been said before. Which was, unsurprisingly, quite a bit!
It is also the work that taught me the most about how innovation actually manifests in the world, far more than any book I’ve read or companies I’ve worked with or invested in. It’s also dense with my personal lens on how I look at the world - that of a networked world - and seeing how innovations can percolate through and impact others was extremely useful.
Self recommended!
Other essays you might have missed, but I loved writing the most: Note, these are not reader favourites or most shared, but the ones that I had the most fun writing.
Notes on social media and the extreme problems of discovery - Discovery is the original sin of the modern age on how finding things has become the bottleneck today, and We live in a world that social media built on how much of the modern discourse around tech revolves around the reactions we had to social media
The closest I’ve come to talking about how best to live a worthwhile life, The curiosity theory of everything, on the only real fundamental underlying driver that has shown how to push us forward
A very important question, on Where are all the robots? I ask why we don’t yet have a Henry Ford to create robots to do work for us, including at home. I think this is one that will get answered very well in the next year or three.
An investing history, in People always put their money in futures they predict. On the difficulty of investing without having a belief of some sort about the future. Might be my favourite investing article I’ve written.
A review of Brad DeLong Slouching Towards Utopia. Highly recommended, not just as a tour de force through the long 20th century, but multi-threaded in how many other books it makes you think about and read. Magisterial.
More about AI below, but one I personally love is the beginning of Homebrew Analyst Club, through Computer used to be a job, now it’s a machine; next up is Analyst.

Now, onwards to AI, which was a major part was my thinking in 2023. It could only have been thus, after all. Explaining part of it to someone is also how I ended up writing Building God, as a way to teach myself what I learnt and to structure my thoughts.
Many such cases.
(By the way I’ve been meaning to create the book as a wiki, but haven’t had the time. If someone wants to volunteer, I’d be eternally grateful !)
I finished writing sometime end June, in a somewhat frenzy, and since then have been collecting more papers and github links as the field continues to go through a Cambrian explosion. The Chinese LLMs came up and are … pretty good! Yi, Qwen and Deepseek models are actually quite good. We made excellent progress in quantisation with advances like QLORA. There was a survey in Feb 2023 that looked at basically creating a scaffolded version of this.
So I thought we’d take a look at each of the categories I said would be crucial to help build an AI scientist - such as memory, tool usage, continuous learning and recursive goal setting, and underlying architecture - and see what progress they’ve seen!
The following are a tour through the papers that I found useful, and not necessarily a comprehensive lit review, since that would take far longer than and essay and end up in another book, and I don’t have the time for that yet! I’ll also spoil the ending by saying what we haven’t yet seen - easy modality in the real-world, seamless coding and error correcting across a large codebase, and chains of actions which don’t end up decaying pretty fast. Though each of these, as we’ll see, have seen progress.
Memory
First, and perhaps unsurprisingly, Memory is seeing the biggest shift. As the hedonic treadmill keeps speeding up it’s hard to keep track, but it wasn’t that long ago that we were upset at the small context windows that LLMs could take in, or creating small applications to read our documents iteratively to ask questions, or use odd “prompt-chaining” tricks.
All that’s changed. Context windows expanded a lot! We’ve had equally large benefits from Tree-Of-Thought and Chain-Of-Thought and RAG to inject external data into AI generation. These are all ways ways to let the LLM “think out loud”. And though there are limitations to this (LLMs still might not be able to think beyond its training data), it’s of course hugely valuable and means we can actually use them for real world tasks.
It’s worth noting that most of the methods here are equivalent to better prompting techniques - finding ways to incorporate different and more relevant pieces of information into the query itself, even as we figure out how much of it we can actually rely on LLMs to pay attention to.
Multimodality
I also wrote about how multimodal LLMs are coming. We can now see them in action. You can upload an image to GPT and it will tell you what it is! And this multimodality incorporates everything from images to video to real world navigation. Papers like AnyMAL from Meta are particularly interesting.
present Any-Modality Augmented Language Model (AnyMAL), a unified model that reasons over diverse input modality signals (i.e. text, image, video, audio, IMU motion sensor), and generates textual responses. AnyMAL inherits the powerful text-based reasoning abilities of the state-of-the-art LLMs including LLaMA-2 (70B), and converts modality-specific signals to the joint textual space through a pre-trained aligner module.
As are companies from Runway to Scenario and more research papers than you can possibly read.
They’re still not great at compositional creations, like drawing graphs, though you can make that happen through having it code a graph using python.
Here’s another interesting paper where researchers taught a robot to walk around Berkeley, or rather taught to learn to walk, using RL techniques.
We thus illustrate how LLMs can proficiently function as low-level feedback controllers for dynamic motion control even in high-dimensional robotic systems.
I feel a weird kinship with this since I too helped teach a robot to walk in college, close to two decades ago, though in nowhere close to such a spectacular fashion! In any case, its only a matter of time before “multi-modal” in LLMs include actual movement modalities that we can use - and hopefully get some household robots as a treat! This, along with the improvements in Autonomous Vehicles for self-driving cars and self-delivering little robots or drones means that the future will get a lot more snow crash than otherwise.
Tool usage
And the core part, of being able to use tools, is being solved step by step through models like Gorilla. It’s like the old days of API wrangling, when you needed to actually connect them all to each other one by one, and then fix them when they changed or broke. But here’s it’s schemas to connect to all sorts of endpoints and hope that the probabilistic nature of LLM outputs can be bound through recursion or token wrangling. In their own words.
Gorilla is a LLM that can provide appropriate API calls. It is trained on three massive machine learning hub datasets: Torch Hub, TensorFlow Hub and HuggingFace. We are rapidly adding new domains, including Kubernetes, GCP, AWS, OpenAPI, and more. Zero-shot Gorilla outperforms GPT-4, Chat-GPT and Claude.
This isn’t alone, and there are plenty of ways to get better output from the models we use, from JSON model in OpenAI to function calling and plenty more. Tools that were human specific are going to get standardised interfaces, many already have these as APIs, and we can teach LLMs to use them, which is a substantial barrier to them having agency in the world as opposed to being mere ‘counselors’.
Taking actions
Perhaps the biggest shift was the question of whether AI will be able to act on its own. And here, agentic behaviour seemed to kind of come and go as it didn’t deliver the needed level of performance. But it has also stuck around sort of invisibly, as part of the fabric. To put it another way, BabyAGI and AutoGPT turned out to not be AGI after all, but at the same time we all use Code Interpreter or its variations, self-coded and otherwise, regularly. What is this if not semi agentic behaviour!
Perhaps more speculatively, here is a paper from researchers are University of California Irvine and Carnegie Mellon which uses recursive criticism to improve the output for a task, and shows how LLMs can solve computer tasks.
Own goal-setting, and changing its own weights, are two areas where we haven’t yet seen major papers emerge, but I think they’re both going to be somewhat possible next year. We can already find ways to create LLMs through merging models, which is a great way to start teaching LLMs to do this when they think they ought to. I’m sure we’ll see more here in 24.
Architectural headway
And we’ve been making headway with changing the architecture too, to make LLMs faster and more accurate. We’re already seeing much better integration of RNNs which exhibit linear scaling in memory and computational requirements, compared to quadratic scaling in Transformers, through things like RWKVs, as shown in this paper. There are plenty more that came out, including LiteLSTM which can learn computation faster and cheaper, and we’ll see more hybrid architecture emerge.
And one I’m personally most excited about, Mamba, which tries to incorporate a state space model architecture which seems to work pretty well on information-dense areas like language modelling. These are all methods trying to get around the quadratic cost of using transformers by using state space models, which are sequential (similar to RNNs) and therefore used in like signal processing etc, to run faster. They efficiently handle long sequences, which was the major problem with RNNs, and also does this in a computationally efficient fashion.
We’re starting to also use LLMs to ground diffusion process, to enhance prompt understanding for text to image, which is a big deal if you want to enable instruction based scene specifications.
The same thing exists for combining the benefits of convolutional models with diffusion or at least getting inspired by both, to create hybrid vision transformers.
Recently, in vision transformers hybridization of both the convolution operation and self-attention mechanism has emerged, to exploit both the local and global image representations. These hybrid vision transformers, also referred to as CNN-Transformer architectures, have demonstrated remarkable results in vision applications
Or this, using controlnet you can make interesting text appear inside images that are generated through diffusion models, a particular form of magic!

Francois Chollet has also been trying to integrate attention heads in transformers with RNNs to see its impact, and seemingly the hybrid architecture does work.
A particularly interesting one was the development of better ways to align the LLMs with human preferences going beyond RLHF, with a paper by Rafailov, Sharma et al called Direct Preference Optimization. It’s promising!
we introduce a new parameterization of the reward model in RLHF that enables extraction of the corresponding optimal policy in closed form, allowing us to solve the standard RLHF problem with only a simple classification loss. The resulting algorithm, which we call Direct Preference Optimization (DPO), is stable, performant, and computationally lightweight, eliminating the need for sampling from the LM during fine-tuning or performing significant hyperparameter tuning
Oh, and we also seemed to figure out how to make algorithms that can learn how to collect diamonds in Minecraft from scratch, without human data or curricula! That’s via DreamerV3, a personal favourite.
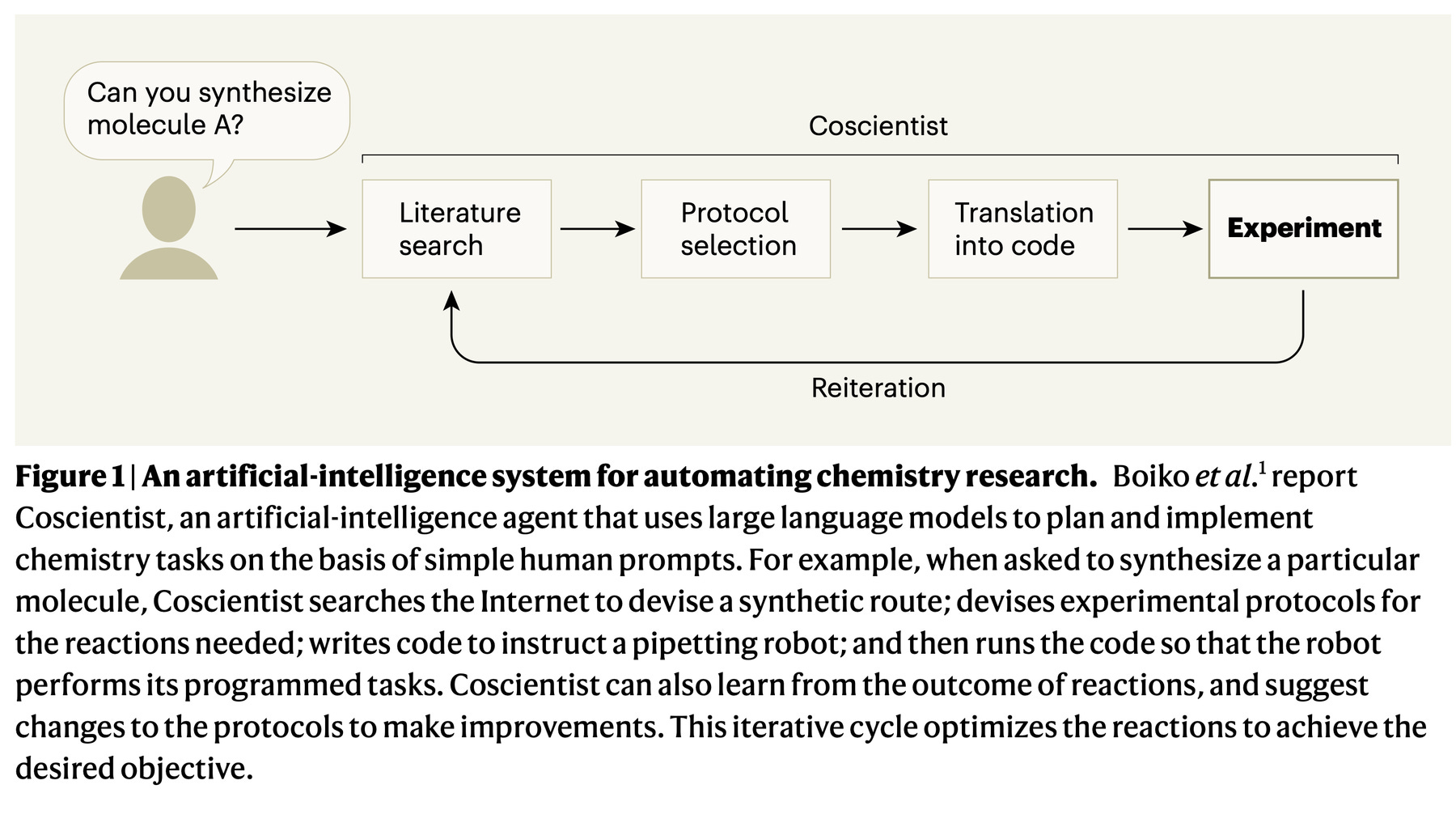
And to make it all worth it, we have papers like this on Autonomous scientific research, from Boiko, MacKnight, Kline and Gomes, which are still agent based models that use different tools, even if it’s not perfectly reliable in the end.
We also saw GNoME in Nov 2023, a great new paper on how you might scale deep learning for materials discovery, that already discovered 736 which also got independently experimentally verified.
I had a specific comment in the book on specialist models becoming more important as generalist models hit limits, since the world has too many jagged edges. Here’s a case study in medicine which says the opposite, that generalist foundation models are better, when given a lot more context-specific information so they can reason through the questions.
I’m still skeptical. I think even with generalist models that demonstrate reasoning, the way they end up becoming specialists in an area would require them to have far deeper tools and abilities than better prompting techniques. Yes, naive fine-tuning might not be sufficient, but that’s also not the only comparison.
It’s purpose built corpus + fine-tuning to teach ways of navigating and understanding that corpus + fine-tuning to teach reasoning, both good and bad + generating examples from the corpus and other prompting techniques to ask questions the right way + using tools to ensure you can get better answers, all working together to help answer specific questions or do complex tasks.
Financial assessment
As a nice little coda, I also had a chapter in Building God called Making Money. I wrote it because ultimately if the theses in the book held up even a little bit then I assumed there would be some alpha in knowing other sectors it might impact beyond the obvious. Since I finished writing it around end of June, I’ve been keeping a spreadsheet of the companies I explicitly mentioned in the book. The short version was that apart from the Big Tech companies who would gain anyway, any increase in deployment of AI would mean that the entire infrastructure which helps surround the endeavour. Memory, networking and chips.

I should confess I thought I was too late to this when I wrote it, and this was basically written into the market. But I’m glad to say that it still outperformed the indices 2x in the last half year. And did slightly better than the big tech cos of MAGMA did together. So, you’re welcome for the alpha.

It was the best of times, and for the Canon it was not the worst of times. Throughout this year I never once felt writing was difficult, only that I couldn’t type fast enough to put what’s in my mind on the page. The 100+ unfinished essays on my notion mock me daily. I felt a pull in my writing which was fun to follow, and I did follow it through some deep research. I learnt an enormous amount and hopefully managed to convey some of that here.
And most of all I loved hearing from you. It’s a constant source of surprise which parts resonate with whom, and it never, ever, ever, ever gets old. At the risk of repeating myself, I love you guys.
What’s more, I can already feel 2024 is going to be even more interesting! There’s so much going on in the world, and there’s so much to dive deeper into and learn and write about. From every corner of science to technology to us discovering how to live in this new culture. From laws to literature. From science fiction to science fact. We’re living in the hinge of history. We live in interesting times.
I’ll see you there. Happy new year!

So much win! Kudos Rohit 💚 🥃
Always interested to read your posts!