
How do you govern something that's part software and part people?
No silver bullets: a proposal for AI governance

I wrote an essay recently at Freethink on the optimist case for AI development that you might like.

If your news feed is anything like mine, there’s been nothing but AI on it, and much of it about how much you should be scared of it. It makes sense, because we live in interesting times. Like most powerful technology, I think sensible regulations if needed could be useful, though what these should be isn’t really talked about enough.
The systems of today are powerful. They can write, paint, direct, plan, code, and even write passable prose. As the discussions about AI heats up we seem to be rapidly heading towards a world where we will have national, international, corporate and nonprofit groups trying to evaluate and figure out if it’s dangerous or not.
Which means figuring out what it can and cannot do has become of the utmost importance.
And with this explosion of capabilities, we also have an explosion of worries. Like the tweet-length letter where multiple leaders in the field signed on to wanting to stop AI superintelligence from destroying the human race.
The more fanciful arguments about how artificial superintelligence is inevitable and how they’re incredibly dangerous sit side by side with more understandable concerns about increasing misinformation.
In seeing some of these current problems and projecting them into future non-extant problems, we find ourselves in a bit of a doom loop.
It's as if we've turned the world into a chess game. In chess, you rarely keep playing up until the moment you actually checkmate someone. You only play until the inevitability of that checkmate becomes clear. It might still happen 10, 15, or 30 moves down the road, but the players can see it coming.
Real life isn't like this. We live in a vast unpredictable Universe that we literally sculpt as we go along. There are far more variables at play than we can feasibly determine, which means analytic solutions come up short1.
What you could do is take the historic view and see this extraordinary fear, or range of fears, as the latest successor to a fine tradition of worrying about the end of the world. What we seem to be doing is taking a futuristic view and backfilling all the horrible things that might happen.
With the power of banal truisms, we’re being inevitably led to sweeping conclusions.
We’ve done this over and over again in our history, of trying to identify the best methods or metrics to evaluate or target, while accidentally goodharting ourselves2.
Frustratingly there hasn’t been a good breakdown of the actual questions involved in getting to an answer, or a structured framework to have the discussions around.
The existing proposals are pretty skeletal, especially considering people think it will literally end our world. While we probably could do with legal liability or regulatory scrutiny, but by and large these aren’t answers, they’re the beginning of more questions3.
Or here’s a blueprint from the UK, and here’s one from the White House, which are both pretty sensible, but feels like they’re at far too high a level (“you should not face discrimination by algorithms”). They really don’t talk to what’s unique about today’s AI.
When Sam Altman talks about the need for regulating large models, that’s a start, but that also brings up more questions. Is it sufficient, and what about the perverse incentives it will inevitably create to link smaller models together4?
So, let’s see if we can construct a framework. I’d posed a longer list of questions before, so I won’t go through them again, but suffice to say while there is a great deal of concern there isn’t a great deal of rigour. To get an answer to how we should regulate AI there are two key questions I think we ought to think more about:
What are LLMs? Are they like regular software? Are they cognitive beings? Are they “employees”?
What are the actual failures we are worried about? Spanning technical problems, software misuse and societal harms, across time-frames.
What are LLMs
Large language models are a little bit like a “do everything” creation which can write, paint, code and basically do almost anything. Which is both what’s amazing about it (you get to ask it to rewrite your resume or write code) and what’s terrifying (who knows what it might be able to do).
When it comes to AI models, especially as they get better than we could’ve imagined, it can become incredibly difficult to figure out what all they can do. But it’s hard, because we don’t have a good enough theory of what it actually is.
I think Ethan Mollick wrote it best, so I’ll quote:
The biggest issue with “getting” AI seems to be the almost universal belief that, since AI is made of software, it should be treated like other software. But AI is terrible software. Or rather, while Large Language Models like ChatGPT are obviously amazing achievements of software engineering, they don’t act like software should.
We want our software to yield the same outcomes every time. If your bank’s software mostly works, but sometimes scolds you for wanting to withdraw money, sometimes steals your money and lies to you about it, and sometimes spontaneously manages your money to get you better returns, you would not be very happy. So, we ensure that software systems are reasonably reliable and predictable. Large Language Models are neither of those things, and will absolutely do different things every time. They have a tendency to forget their own abilities, to solve the same problem in different ways, and to hallucinate incorrect answers. There are ways of making results more predictable, by turning down the level of randomness and picking a known “seed” to start, but then you get answers so boring that they are almost useless. Reliability and repeatability will improve, but it is currently very low, which can result in some interesting interactions. … What tasks are AI best at? Intensely human ones. They do a good job with writing, with analysis, with coding, and with chatting. They make impressive marketers and consultants. They can improve productivity on writing tasks by over 30% and programming tasks by over 50%, by acting as partners to which we outsource the worst work. But they are bad a typical machine tasks like repeating a process consistently and doing math without a calculator (the plugins of OpenAI allow AI to do math by using external tools, acting like a calculator of sorts). So give it “human” work and it may be able to succeed, give it machine work and you will be frustrated.
You should read his whole article, but the gist is quoted above. Software, which is meant to be predictable and testable, are a bit like LLMs. And they’re also like humans, who aren’t as reliable but are incredibly versatile.
Failure modes
Now, there are a few ways in which failures can happen. It looks like there are 4 ways it can go wrong.
Technical failures
LLMs can sometimes produce inaccurate or nonsensical outputs due to their lack of true understanding of language semantics. For instance, they may describe a painting as "jarring," a term more commonly associated with sound than visual art, indicating a lack of semantic understanding.
LLMs can also struggle with bias encoded in the text they learn from, such as gender, race, or religious bias. Furthermore, there is an unequal distribution of language resources available for building these models, resulting in a lack of representation for many languages.
The biggest issues here are hallucinations, which we don’t know how to anticipate or control, and prompt injections, which we don’t know how to eliminate!
Software misuse
There have been instances where LLMs like GPT-3 were misused for various purposes including disinformation campaigns and spreading of spam content. This is a major part of what folks like Gary Marcus talk about. While we’ve seen individual instances, like a fake kidnapping using someone’s voice, or deepfake videos of Tom Cruise acting like a sea turtle, it’s not yet become a large epidemic.
Social externalities
This is a bit more speculative, because the worries here are if using LLMs will have eventual bad outcomes, sort of like a supercharged social media. It will destroy jobs, creating an economic catastrophe, and dramatically increase inequality or destroy privacy. Deepmind put out a report detailing a list of harms, which included these and many more.
Software behaves badly
This one is the most speculative, and the one that’s most linked with AI doom worries. It is where autonomous AI actions cause harm to humans or humanity as a whole. While we’ve seen some autonomous agents like AutoGPT, we know of no systems where this has been done, much less where it’s planned to be done, but it’s useful to keep in mind for systems like the military.
So, how should we evaluate them?
If LLMs are like software, then we have a set of principles to fall back on. We QA it to see if the behaviours match what we’d expect, we red-team it to test it against intrusions, we do white-hat hacking to find exploits and so on. This isn’t exhaustive, since any software of even medium complexity has an incredible number of ways in which it can cause bugs, but it is a time-tested way to error-correct towards better functionality!
But it doesn’t really help test for capabilities. That’s because most software doesn’t have an unknown list of capabilities, it kind of does what it does more or less, and for the real world you can rely on the users to figure out new and clever ways of using it. That, I think it’s fair to say, is not quite the same.
If they’re like employees on the other hand, we’re in a different bucket. If you haven’t gotten sucked into Berkson’s Paradox and managed to hire someone good, then it’s a bit of a journey to figure out what they’re good at - both today and eventually. You can do tests and evaluations though they’re not very accurate. You can do IQ tests or psychometrics but they too are not that useful. Mostly what you can do is to have common sense hiring practices and plenty of on-the-job training.
Let’s take it in turns. The first option is to treat them like software. In software, we have a few time-tested ways of figuring out how to evaluate their abilities and performance.
I. Technical Failures:
Unit Testing: Consider this the 'linguistics' phase of our exploration. In unit testing, we break down the software into the smallest, standalone components - or 'units' - and test them individually. This is akin to understanding the basic grammar and vocabulary of a new language. Each unit test ensures that a specific component works as intended.
Performance Testing: The AI model is evaluated under various conditions, such as heavy user load, different types of tasks, or limited resources, to identify any bottlenecks or performance issues that could potentially lead to technical failures.
II. Software Misuse:
Integration Testing: Once we understand the individual words and grammar rules, we start forming sentences. This is where integration testing comes into play. We begin combining multiple components and testing them as a group. It's like testing how well our newly learned words and rules work together to form coherent sentences.
Security Testing: Here, the AI's security features are evaluated to ensure it can withstand attacks and protect the data it handles. We test the software's security features, ensuring it can withstand attacks and protect the data it handles.
III. Social Externalities:
Acceptance Testing: This step is akin to measuring user satisfaction. The AI model is tested to confirm that it meets the required specifications and satisfies the user's needs. This is the equivalent of having a native speaker review our work. Acceptance tests are conducted to confirm that the system meets the required specifications and satisfies the user's needs.
IV. Software Behaves Badly:
System Testing: Going one step further, we start to create stories using our sentences. This is system testing, where the entire system is tested as a whole to ensure it works as expected. It's akin to understanding the context, the nuances, the idioms, and the cultural references of a language.
The last one doesn’t really apply to software, but it sort of does to an AI, so let’s stretch the metaphor to fit for now.
A second option is to think of it as an employee. Here too we’ve had a reasonably long history of trying to figure out ways of evaluating employees and testing them.
I. Technical Failures:
Installation Test (Hiring Process): Just as we verify if a software installs correctly and runs without errors, the initial setup and basic functioning of the AI system should be checked. This stage can help identify potential technical failures, similar to how the hiring process assesses whether a candidate's initial presentation, communication skills, and responses during the interview suggest they would be a good fit for the organization.
Unit Testing (Individual Task Completion): Analogous to examining an employee's ability to complete individual tasks, the AI system should be tested on its ability to accurately perform individual tasks. Factors such as the quality of work and speed of task completion are useful to understand here.
II. Software Misuse:
System Testing (Strategic Contributions): Like evaluating an employee's contribution to the overall goals and strategy of the organization, the AI system's alignment with overarching goals should be assessed. This step would serve to prevent misuse, as any application of the AI that is inconsistent with these goals would presumably constitute misuse.
III. Social Externalities:
Acceptance Testing (Customer Satisfaction): Customer satisfaction is a key indicator of how users interact with and respond to the AI system. We can somewhat measure an employee's performance through the lens of customer satisfaction, if they’re directly in front of the customer anyway.
Performance Testing (Performance Under Pressure): Assessing how the AI system responds to high-stress situations, such as large-scale or complex requests, can help identify any social externalities that could arise from AI failure under pressure. This is akin to evaluating an employee's ability to manage time, prioritize tasks, and maintain work quality under high-stress situations.
IV. Software Behaves Badly:
Integration Testing (Team Project Participation): Like evaluating how well an employee functions within a team, the AI system's ability to integrate with other systems or teams should be assessed. Any harmful autonomous actions by the AI could disrupt this harmonious interaction, making this a critical stage for assessment. Just as in team evaluation, the AI's ability to collaborate and contribute to group objectives would be assessed.
Creating a framework
Since LLMs are somewhat of a mix of software and humans, we should probably mix the testing methods we’ve identified above.
Like software it has specific components that can be analysed as engineering, for instance when it comes to items like prompt injections or whether it will give you wrong answers. Similarly they’re like employees in that you don’t really have a strong grasp on their actual abilities and it’s a mutual voyage of discovery. You can’t rely a hundred percent on them because they might get it wrong through incompetence or misunderstanding or malice.
And if you mix the recommendations together above, then you start to get a pretty comprehensive list of evaluations that ought to be run, some more linked to software and some linked to employee modes.
I. Technical Failures (Corresponds to Preparation):
Training and Learning Evaluation (Software Mode): Assess the quality and diversity of the training data, the learning algorithm's ability to generalize from this data, and test the delta in training that occurs with difference in training data. This process helps in predicting and preventing technical failures by ensuring the AI has been trained properly.
Teaching Speed Evaluation (Employee Mode): Test how quickly behaviours and outputs can be taught to a smaller model, gauging the "no-gradient" limits of possible to see how quickly a “specialised” sub-model can be set up. This understanding can guide how quickly a model could be re-trained or adapted, reducing chances of technical failures.
II. Software Misuse (Corresponds to Skills & Capabilities):
Unit Testing of Individual Skills (Software Mode): Test each individual capability of the AI. Ensuring each function works as intended can prevent misuse by limiting opportunities for malicious users to exploit malfunctioning or poorly performing aspects of the software.
Integration Testing of Combined Skills (Software Mode): Assess how well the AI combines its skills to perform complex tasks. This testing can expose any vulnerabilities that might be exploited for misuse when the AI's capabilities are used together.
Complex Task Execution (Employee Mode): Test the AI's ability to autonomously define and execute complex tasks, similar to a PhD thesis. Monitoring how the AI handles these tasks can help identify potential areas where misuse could occur, especially in situations requiring complex and nebulous objectives.
III. Social Externalities (Corresponds to Interaction):
Fact vs Style Analysis (Employee Mode): Measure models for style and factuality of responses. The evaluation of responses can offer insight into how the AI interacts with users and the potential social impacts of those interactions.
User Satisfaction (Employee Mode): Measure user satisfaction with the AI based on user feedback, usability tests, and metrics like task completion rate or error rate. Understanding user satisfaction can help anticipate and minimize unexpected social impacts from AI deployment.
IV. Software Behaves Badly (Corresponds to Robustness & Reliability):
System-Level Evaluation (Software Mode): Evaluate how well the AI functions as a complete system. A comprehensive system-level evaluation can detect potential areas where the AI could behave harmfully due to system-wide issues.
Performance Under Different Conditions (Software Mode): Evaluate how the AI performs under a variety of conditions, such as different types of tasks or under high demand. This understanding can aid in predicting and mitigating harmful outcomes from autonomous AI actions under different conditions.
Robustness and Reliability (Software Mode): Evaluate the robustness and reliability of the AI, testing its ability to handle unexpected inputs or situations, and its resilience against attempts to exploit its vulnerabilities. A robust and reliable AI is less likely to behave unpredictably or harmfully.
Applying the framework
Now we can sort of lay these and expand across the timeframes - what we see today, what we’re likely to see in the medium-term, and what could happen in the long run.
Which means we can look at the problems that exist, and start having a sense of what they look like, across timeframes. Here’s the data.

So how can we actually look towards solving it? So here are the possible ways we can think about trying to solve them.
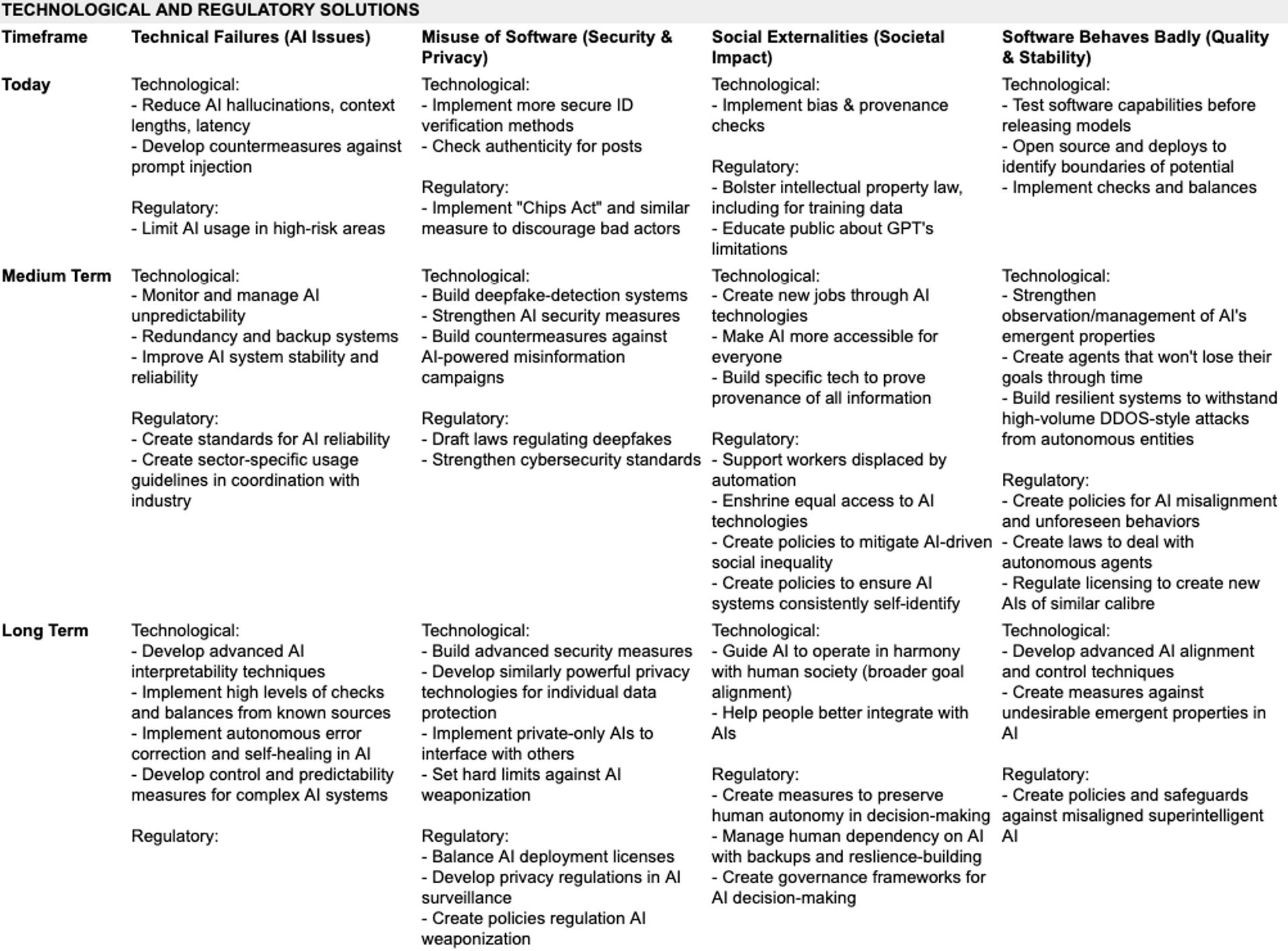
There is no silver bullet for finding the “one true way” that will help us evaluate and understand large scale AI models. We don’t have them for large software packages, much less human beings. Instead we use a large number of heuristics, tests, on-the-job performance, and cobble together an evaluation that hopefully is more right than wrong. And that’s what we’ll have to do now too.
Conclusion
All of this brings us back to today. What we have today is an incredibly powerful and fuzzy processor. It can manipulate information in almost any format. Text, video, audio, and images can be broken down and built back up in new forms. In doing so, it hallucinates and has to be led through examples and careful phrasing. It can be taught (albeit painfully), can be given memory (though not infallibly), and can be used to great effect as our daemons.
These language models today are the reflections of our training data and methods. Their foibles are our foibles reflected back at us. And we're getting better! GPT-4 doesn't make the mistakes GPT-3.5 made.
We can’t know if this is closer to a local optima where it languishes or the beginning of an exponential Moore’s law curve. We can’t know if it’s months away from sentience or decades. And we can’t know if it’s intelligent, in part because we haven’t managed to properly explain what we mean by intelligence.
We don’t even know the limits of what we’ve created well enough, and we have not seen a single instance of it actually causing any sort of widespread mayhem. Instead, the closest societal catastrophe AI has caused is making homework essays a thing of the past.
Meanwhile, it’s given us the ability to get a second opinion on anything at almost no cost, from medicine to law to taxes to food preparation, even though it’s not fully reliable yet. Today's technology already promises a release from the great stagnation, rekindling sluggish R&D and hastening medical breakthroughs. Whether in energy, materials, or health, we advance and we improve. Blocking this path, you dam the river of progress and cast a shadow on collective well-being.
As policymakers, we have to focus on what we can know. When we don’t know what will happen, we have to rely on models. As we saw during the recent Covid crisis, this too is liable to fail even in straightforward cases.
So we tread carefully. The framework above is a way to think about what we know and separate our assumptions from our worries to be tested by reality.
Coda
All that said, if you’re still focused on the possible costs we might end up paying, there is one thing that I think is worth thinking about: the problem we see with widely distributed systems today. Once the use of AI systems gets widespread, we could see algorithmic flash crashes. Just like we see odd behaviour and odd positive feedback loops when multiple algorithms interact in unforeseen and unforeseeable ways, like with the flash crash in the stock market, we might see similar things occur elsewhere5.
After the flash crash happened, we started regulating high-frequency trading to stop this from happening again. We introduced circuit breakers, improved market transparency, and improved the infrastructure. This, and constant vigilance, is the price we pay to make things work better through automation. Once we knew the boundaries of how things failed, we figured out ways to work around them.
Our ancestors used to jump on ships and sail into unknown waters undeterred by the dragons that lay there. We should do no less.
This approach only works if we try to nail down our beliefs in the form of something that can be tested or falsified. The destructiveness of nuclear weapons is something we can test, as is biological experimentation.
AI is not like that. We have a range of fears with varying degrees of realism, from the very sensible worry that we shouldn't hook up our air traffic control to an LLM anytime soon, to the completely out-there view that an AI will become superintelligent and cause human extinction through a sort of disinterested malice.
A few examples:
The Absurd Theatre of Standardized Testing: Picture a world where children are not judged by their curiosity or their capacity for wonder, but by their ability to fill in the right bubbles on a scantron sheet. Welcome to the 20th century's grand experiment in education, where we reduced the rich tapestry of learning to a game of 'Guess What the Test-Maker Thinks'. The irony, of course, is that in our noble quest to quantify educational success, we ended up spawning a generation of brilliant test-takers who might not remember what photosynthesis is, but boy, do they know how to eliminate the wrong multiple-choice options!
Clickbait: The Siren Song of the Internet: Ah, the Internet—a place where even the most banal articles are dressed up in the digital equivalent of a neon sign screaming "Click Me!" What started as a simple measure of interest—click-through rates—morphed into an unholy arms race of sensational headlines and outrageous claims. The value of content? A quaint concept trampled under the feet of the hordes rushing to click on "You Won't Believe What Happened Next!"
The Metric Maelstrom of the Modern Workplace: Imagine being a software engineer, your worth measured not by the elegance of your algorithms or the robustness of your code, but by the sheer number of lines you can churn out. Or picture yourself as a customer service rep, your performance gauged by how quickly you can get customers off the line, rather than by their satisfaction. Welcome to the bizarre funhouse mirror world of productivity metrics, where quantity trumps quality and the true nature of work gets lost in a flurry of numbers.
Data speeds in internet service: In the internet service industry, advertised connection speeds have often been used as the main benchmark to entice customers. However, focusing solely on speed can overlook other important aspects of a good internet service, like reliability, latency, and customer service. This has led to situations where ISPs promise incredibly high speeds but fail to deliver a consistent and reliable service.
What sort of liability, and for what? For LLM creators or also for Nvidia who supplies the chips? What about the users?
There are also interesting implications of how “Large Language Models” and “Small Language Models” work with each other, if the Small Models can be linked together to create equivalent abilities.
There is initial research indicating that imitating proprietary LLMs, but using GPT-4 output to train a LLAMA model, for instance, only transfers the mimic style but not factuality. That emergent abilities is a mirage.
This means, for evaluation purposes:
If the Large Language Model really do demonstrate emergent properties, which is in contention, which are absent in the Small Models, then there is a very clear risk associated with the very large LLMs that we should focus on.
However, if most of the value can be brought to life from Small Models linked together, especially if the capabilities are more about the “style” of imitation as opposed to “knowledge”, then the smaller models might even be superior. This also poses a death knell for any evaluation framework solely focused on size.
The mitigant I see is that AI systems are smarter than the dumb, trend-following autonomous bots that caused the flash crash, yet it remains a truism that complexity creates possible catastrophic failures.
I enjoyed this. Some nice suggestions.
What an unusual article! Instead of fear-mongering and making up fantasy scare scenarios, you have written a thoughtful and helpful piece on benefits and approaches to reducing risks. It seems that there are far fewer of those us taking this approach than there are of those hyping both short-term and long-term dangers, with rarely a word to say about massive benefits.