
"Oh Bing, Please Don't Be Evil"
Large language models aren't search engines like Google, they are fuzzy processors, a new lifeform entirely.


I. The battle of titans
The news is filled with people talking about Google’s demise. That they lost $100 Billion of market value when Microsoft announced that Bing, its search engine that makes $10 Billion of revenue and has 8% market share, will incorporate the magic of OpenAI and ChatGPT.
Let’s leave aside for a moment that a drop in market capitalisation for a publicly traded stock on the basis of a press conference is a) a thing that happens depressingly often, and b) not something that helps in causal understanding all that much.
But the question I wanted to test was, how much of the hype is real? And so, first, I started with: what does Google say when you search for Bing?

Well, turns out it does quite well. There is the link, of course, and a bunch of news stories about Bing.
But the interesting bit is to the right, where there is a snippet of information extracted about Bing, directly from Wikipedia, with the relevant info just right there. This is what Google calls its “featured snippets”.
So Google does a remarkably good job of finding news pieces that are relevant to the questions and direct answers from sources where it helps. Where it falls foul is that by its own policies (below) it’s hamstrung in how it can use the information from the websites it crawls to summarise and use them. It’s the same fight that we’re seeing in Getty Vs Stability AI, just playing out on a much larger canvas and with the most profitable business ever hanging in the balance.

But I wanted to see if we did change the methodology, how good are the results actually! To test, I chose the top queries that Bing itself highlighted in the Bing site, which presumably are the best of what the new Bing can do. And I searched each one on Google too and looked at their top results. There are way too many screenshots for each one, so here’s the summary table. (You can play along at home if you’d like, or ask me and I’ll send it to you.)
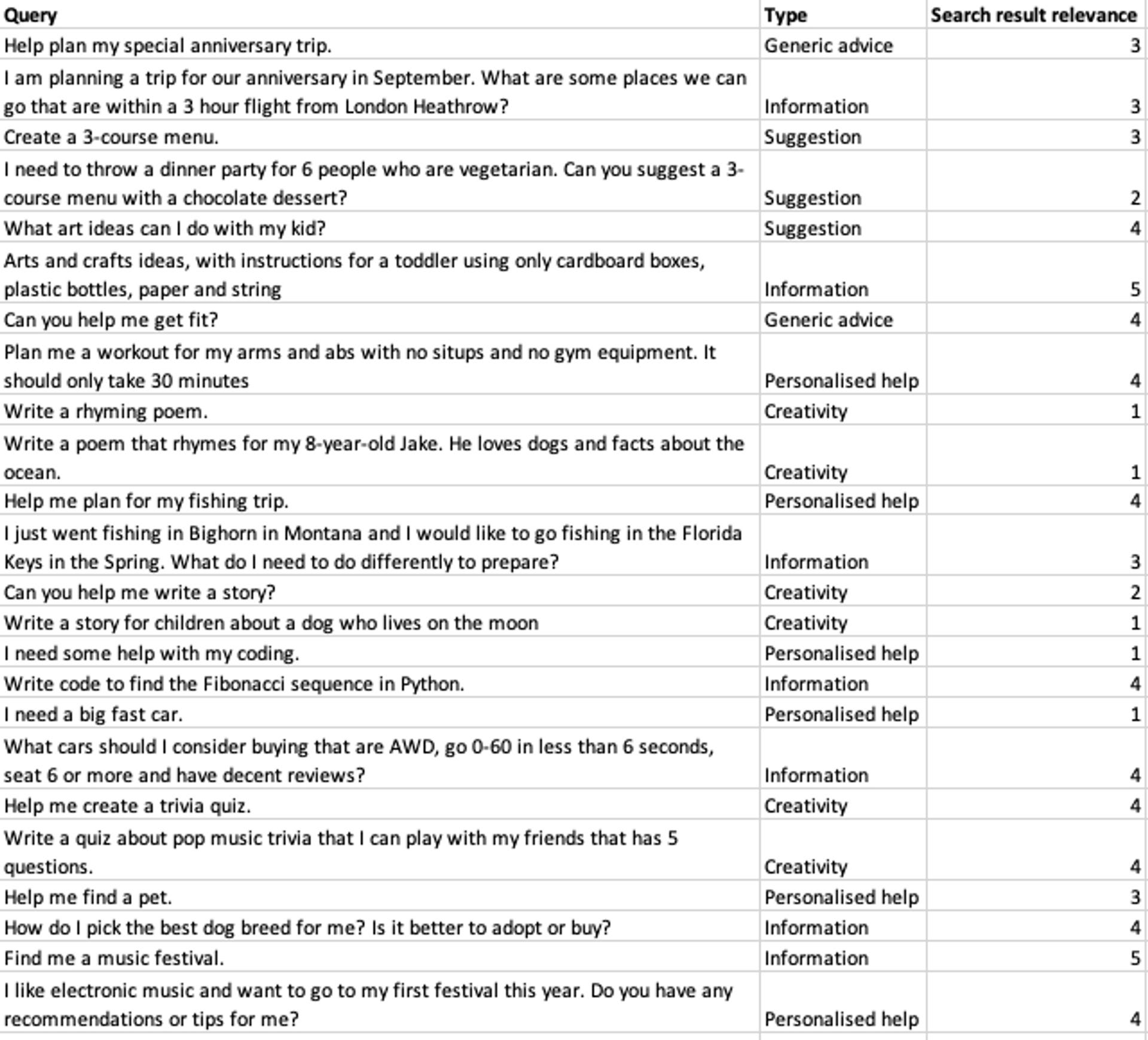
I classified the questions in somewhat arbitrary fashion, to try and determine what each query was actually trying to get at, and how good Google was at it.
The first thought is that the “Creative” questions are the ones Google does worst at. Which makes sense, since those are questions to get a particular output, rather than follow a particular process or gather information about a particular input.
The second thought is that while a large chunk of Google queries, especially done over Voice, already provide you with a snippet of an answer, none of these queries did so. While this makes sense (if you could get the info easily from a website, why would Bing prominently display them), it’s an interesting thing to keep in mind.
But, out of the 24 queries from Bing (12 with the subject and 12 as detailed personalised questions, the way they split it)
at least 15 had the “people also ask” section, with specific questions and answers associated with it
7 had video links in the answers
I have difficulty looking at this and thinking Google is dead.
The simplest reason being they could just literally take the first three search result web pages, summarise it through whatever LLM, and already do better than Bing. And I do mean literally, look at the results that come when you search for things, and you can summarise the answers. In fact, they’re already doing it!
The interesting thing here is that the data here is strictly “okay”. While the chat response feels like a complete response, it is not. It requires external consultation based on individual circumstances. It is fairly generic. And it’s mostly a regurgitation in summarised form of what the video says on the left.
Or to rephrase, one way to think of Google searches is that they’re a combination of:
What queries: Need to find information
How queries: Figure out how to do something
Why queries: Answer causal questions
Do queries: To perform an action (eg comparison of products)
For the What and How, Google does admirably well. How is harder, it depends on the question, but Google can summarise its results, if its legal department says yes, and do well. Where it lacks is the “Do” queries, especially if the Do queries are net new (”write a childrens book with a dinosaur and the earth’s core”).
What percentage is that likely to be of all queries? I don’t know. What percentage of all search will shift because of the existence or ability to do this? I also don’t know. I suspect not that much!
Which brings us to the more existential question, of what it is about the underlying tech that’s causing the furore.
II. What exactly are LLMs? Well, they are fuzzy processors
From playing with it for quite a while, I have an overarching theory of LLMs. Since the dawn of computing, we’ve been dealing with them as dumber versions of ourselves. As Douglas Adams said.
By the time you've sorted out a complicated idea. into little steps that even a stupid machine can deal with, you've certainly learned something about it yourself. The teacher usually learns more than the pupil.
This, however, has limits. When the complicated idea gets large enough, when you make it with the help of a large number of people, when parts of it interact in unforeseen and unforeseeable ways with other parts, then you’re stuck learning not that much with additional atomisation.
This is why large codebases in companies often behave as if it’s got a life of its own. Problems proliferate where it shouldn’t, and troubleshooting is a bit like Dr House diagnosing Lupus.
So even when the input is highly deterministic, the output can occasionally be chaotic and somewhat unpredictable.
We’re having this debate between ourselves of how to think about what ChatGPT actually is. It’s:
a captured god
a precursor to intelligent life
a stochastic parrot
a liar
a plagiarist
fancy copy and paste
a p-zombie
They’re all somewhat true, though ChatGPT itself denies it.

What is a better analogy, I think, is that they are fuzzy processors.
Like the opposite of Douglas Adams’ infinite improbability drive, which creates a field of improbability, it’s an infinite probability drive, striving towards finding the most probable answers and autocompleting its output even word by word.

What sort of a fuzzy processor is it? Well, Wolfram has one of the best explanations of what goes on inside it that I’ve seen. The core is that in analysing and understanding the statistical nature of our language, it has, in a rather Wittgensteinian way, figured out the “rules” of that language game. And since the game is set in our real, human, life it has understood aspects of how we work. And the rules tell it what text is supposed to come after a particular word.
Fuzzy processors are different in the sense that they are not deterministic. The answers you get to prompts can be perfect encapsulations, outright lies, summaries with 20% missing, or just outright hallucinations.
Which also makes searching for things with it harder depending on the precision you need in your answers.
Just like searching was a different mode of finding information than libraries before, with its clear tree-structure of information put in very clear boxes, chat is a different process altogether. Fuzzy processors require a lot more effort from you, the user.
This, however, is possibly just fine. Whenever I write a piece of code I have to spend roughly 3x as long Googling and 4x as long troubleshooting. That’s also an issue of the output not matching what I want from an output.
But … but the first fuzzy processor makes different mistakes than what we’re used to. It makes, dare I say, more human mistakes. Mistakes of imagination, mistakes of belief, mistakes of understanding.
To use it is to learn a new language.
All our existing programming languages are about ever-more precisely defining what we want the computer to do, and even when they make programming “easier” it does so by hiding away the complexities behind some abstraction. They do so by using standardised libraries or standard frameworks or common functions or one click API to deploy infrastructure. These are ways we constrain our efforts to only looking at the highest-level of what we need to do. Like all standardisation efforts, it helps us build on top of what existed before.
LLMs are different. All efforts are built out of the primordial soup that is its latent space.
There is no standardisation or consistent quality control, not really. There are some conventions on prompt engineering, but there is absolutely no way you’ll reach the same conclusions even if you followed the same process.
You’ll be close! And for many things, that’s sufficient.
But a fuzzy processor, that’s different. When you can’t trust the output that comes from your input, you have to be far more careful on how you use it.
You can only really use it for things where you don’t know what the output would’ve been beforehand. You can work with it to guide the output towards what you would like it to be, but its closer to sculpting than just searching.
III. The final frontier
I wrote a while ago about how the final frontier for AI was personality, and this is what Bing seems to have nailed, while ChatGPT has not. This brings the question of how we use the fuzzy computers.
Which means, looked at en masse, it feels like the advantages Google has is still true, their ecosystem of browser + extensions + mail is very strong and not easily dislodged. Bing’s search results were always okay, and still is okay, but now it has a new power. How could it win?
A different interface will win
If asking for things via one on one chat is more useful than a text box with a list of answers, then there is an existential risk for Google. This is a UX question.
Is the white text box over? No. They’re both white text boxes. The relevant delta is if you like having a conversation to get to an answer, or not!
A different set of questions will become more prominent
The types of questions that Bing does better at answering are the Creative ones. For those Google can only offer a route to the work someone’s already done. For instance, here’s the Google response vs Bing response on the workout question.


The problem with the result on the bottom is that it’s often incomplete, and incomplete in ways that aren’t easily understandable. The problem with the result on the top is that this too is incomplete in ways that aren’t easily understandable. On the top, you circumvent by finding reliable sources that you can believe, I’m not sure how to solve it on the bottom yet.
Neither of those feel particularly likely.
In fact, the case of Google Vs Bing is fascinating, because it tries to talk about “Search” as one thing. It isn’t. Search is many things. It’s about getting you to the right endpoint quickly. For code, it’s code. For factual questions, it’s an answer. For curiosity driven explorations, it’s the next node you need to get linked to.
Chat is a great way to develop your ideas, like thinking through while talking to someone on the phone. And that’s why it feels like it has clear, overlapping, ways of engaging with how we do search.
The summary then:
ChatGPT is way better at creative tasks
It is somewhat better at specific troubleshooting, with particular questions which require in-context iteration
But it’s absolutely brilliant as an assistant with sass
What this tells me is that CGPT is not a competitor to search at all, but rather it’s likely to substantially increase the surface area of what “search” traditionally meant. It’s a throwback to having a sassy associate to search things for you, rather than doing it yourself, like Hollis Robbins had written about.
It’s like everyone has their own Jeeves, Pepper Potts, Joan Holloway or Passepartout - a perfect assistant who’s also a foil to do the things you don’t want to do, with sassy banter, who is remarkably smart and articulate but content to book your hotels, who’s sometimes even your conscience. They might occasionally get things wrong but that doesn’t matter as much, since you respect the capabilities even if its results aren’t always right.
I currently have a chat window open sometimes, but with personality that might well become all the time. After a very long evolution and many blind alleys, it feels we’re about to get the daemons that Philip Pullman had written about. And that is remarkable!
UPDATE: To test my theory that Google could trivially build this, I made a bot that converted the queries into Google searches, scraped the first 3 results, and summarised the answers. It does really rather well. If you extend the tokens, prettify the results, and rewrite it, this gets to be comparable to ChatGPT instantly. There’s a threat to ad model, sure, but there’s no way Google’s on the back foot!

If you liked this, you might also like:
It's good comparison of what the current state is. Google is still a web search engine after all. It is designed to get results found in the web.
Bing on the other hand is enriched with the integration of ChatGPT to read the found web results and present a summary in natural language of what is may found in those web articles.
Something Google just is not meant to do (yet).
These future natural language search processors could be more enhanced when they would also process the information found videos on YouTube for example. YouTube already creates transcripts of all teh uploaded videos. If those are (kind of fact checked and) also feeded into Bard (or whatever Google will come up with), it could easily compete and maybe even succeed Bing.
It's a great perspective on what one instance of an LLM can do in their current form.
A great thing that Bing can do but search can't is follow a semantic context. As we get better at communicating with it, it can reduce the space of answers for "what" and "how" better than traditional search that's keyword based and where users need to be the one translating the context into the appropriate keywords to type.
I think the interesting area of exploration is when LLMs are combined. One promising method is that they can play the role of verifier and reasoner in a somewhat independent way from the output they need to evaluate. https://learnprompting.org/docs/reliability/diverse