
Why Coase needs Hayek
sometimes smart planners lose to simple markets

So it turns out that when you give a very smart cutting edge frontier model the job of managing other models, it costs four times as much and does worse than just letting them compete. After all if you have access to many models there are three ways to do things. One option is to make the smartest model a hub, and have it route the questions to other models as it sees fit. Another option is for the smartest model to do everything. And a third option is a free for all, for every model to vie for the chance to have a crack at it. A market, as with our work before.
To understand this, like any good scientist, we can do an experiment. The Coasean argument says that we will see an unbundling of firms as transaction costs decline. This will make the mini-firms need to coordinate with each other. How will they do this? Well, you can have some planning, or you can have markets.
So in my experiment, the hub did the thing everyone says agents should do and are good at doing: split the task, delegate, red-team, revise. But it spent four times as much as the market and did worse. The market meanwhile did the thing everyone says current agents cannot do, bid on their own competence, and it still won on cost and tied solo on quality.
Why? Why did the expensive planner frontier model lose to a simplified market whose bidders don’t even know what they are actually good at? What are the right ways to organise a bunch of models to get good work done?
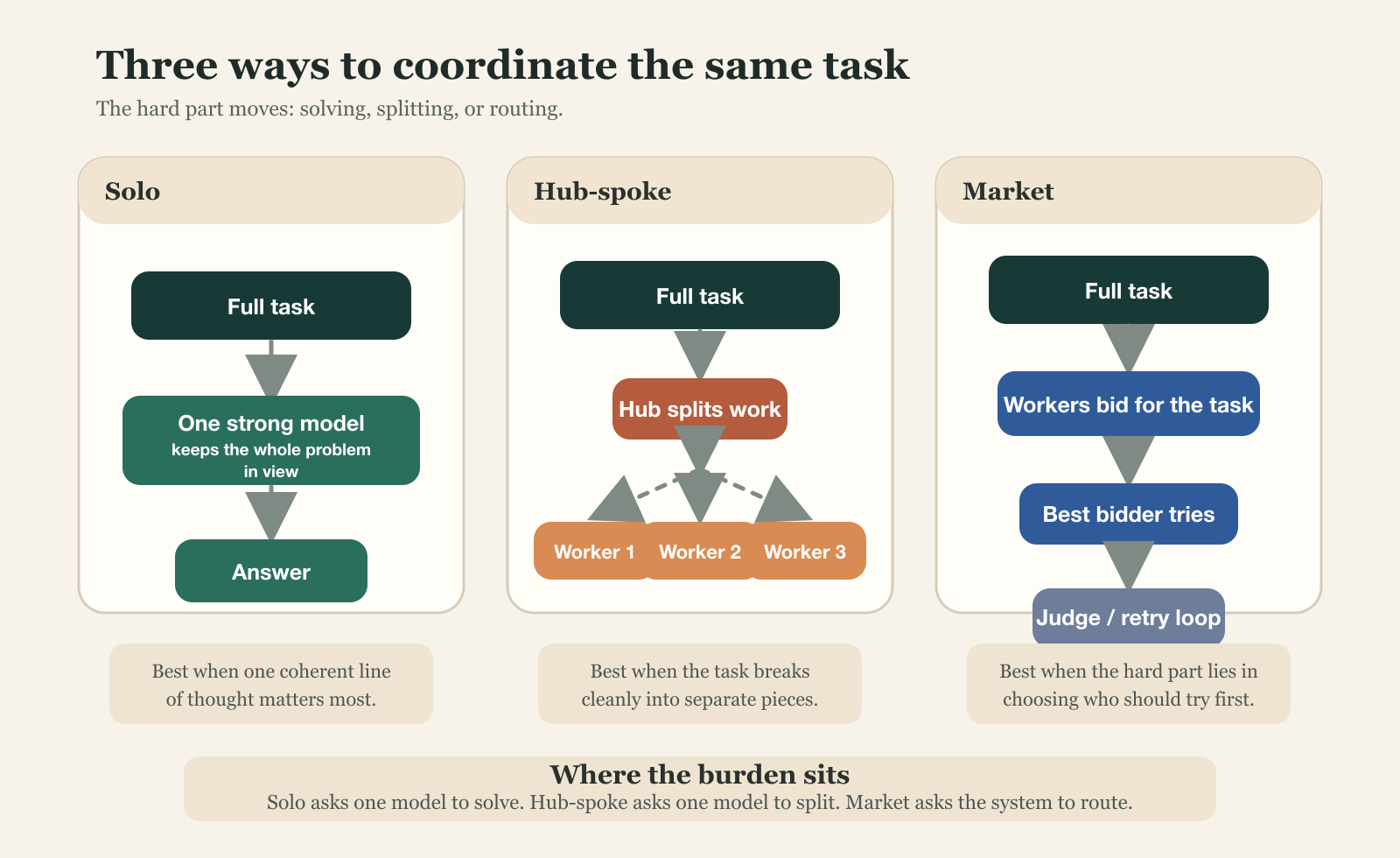
Well, normally, there are three main ways. You could do things yourself, you could delegate to others, or you could let everyone pick what they want. Each of these gives a different challenge to a model:
If it’s a solo try, the hard part is coherence. It doesn’t have the benefit of diversity but has to solve all problems through one state.
With hub-spoke, the burden is decomposition. How well can you split up the tasks and know that another model can solve it. And recombine it after.
With market, the hard part is allocation and retry. Do models know how much to bid, and how well? Can they?
Each such topology has its own success cases and failures. And we can see when each setup works best too.
For this experiment, I used 15 hand-written tasks: five coding, five reasoning, five synthesis, to cover a few of the main tasks we want frontier model systems to do.
A strong model working alone, as the base case
Then, a hub that split the work into subtasks and sent those to three workers, got answers back, did a red-team, then revised
And a market setup, that let three models bid for each task, picked a winner, judged the answer, and updated reputation across the whole run
The market averaged 7.2 out of 10, at a total cost of $1.34, Solo averaged 7.2 and cost $1.69, and Hub-spoke averaged 6.7 and cost $5.33. Markets beat hierarchy here.
But we can look at the specific subsets. In Coding, Solo wno coding-001 (see readme) and coding-005. Solo tied coding-004. Hub-spoke won coding-003. The market won only coding-002.
This is because the coding tasks in this suite rewarded one continuous line of thought. A model had to hold the whole class, the edge cases, the invariants, and the exact behaviour in one place. The interval store wants one design. The LRU cache wants one data structure. The async bug hunt needs to keep the races straight from start to finish. So a large model with sufficient context window can crush it.
Hub-spoke helped most when the task naturally breaks apart. coding-003, the refactor task, fit that shape better than the others. One worker could clean validation, another could clean discount logic, and another result assembly.
The market hurt itself on code in a different way, mainly with bad routing. It routes most coding work to GPT-5.2. Across the 15 coding runs, GPT-5.2 handles 9, Opus handles 2, and 4 runs never fill at all.
Coding seems like one of those topics where keeping the global state in mind is crucial and the ability to find other models who can do tasks which would be modular is useful. In other words the models are better coders than they are good TPMs.
But Reasoning cut the other way. The market won with 7.1. Solo at 5.1. Hub-spoke at 5.2. Reasoning-001, the exact-match probability problem, was the heavy lifting. The right answer, 10/33, appeared only in the market runs.
This is the kind of task where markets can win even though right now the bidding is bad. A brittle reasoning problem does not reward elegant decomposition. It needs independent attempts and failure detection and retries!
Going back to the specific challenge, coding required statefulness and knowledge while in reasoning problems retries brought about diversity.
Synthesis was the “ambiguous middle” category between the two. It needed framing and caring about omissions and tradeoffs. And so we saw the benefits of the market show up here too, vs hub-spoke setups.
This is small n but the smaller lesson is that on a few brittle problems, the bidding and retry loop seems to help. A bad first answer does not end the run since another worker can take a shot. That’s what we saw in the paper as well, though there we were mainly focused on coding, so the extension now to 10 new problems gives us an interesting baseline to analyse!
In MarketBench, when we looked at how models deal with being part of markets, we saw that they’re terrible at figuring out their own capabilities about answering a problem set to them, and in bidding on the basis of that. They lack self knowledge. And while agents are bad bidders and terrible cost forecasters, they’re still useful together vs alternate topologies if they bring sufficient diversity premium (ability to get a new model to try the task out after one’s failed). We see that here too.
Now why does that exist? We can speculate. Models are trained similarly, and sometimes by the same people across companies, but the cumulative effect of how they’re trained makes them different enough in that they perform differently across similar-looking problems. And as we saw in the MarketBench paper, some models are overconfident (Gemini), some are underconfident (GPT) and none are good at predicting what it would take to solve a problem.
We’re used to thinking of the multi-agent future as analogous to our companies, just autonomous. And hub-spoke is the “normal” way of doing things to us, because it resembles an organisation chart. There are managers and workers and review and revision. This is comforting and familiar.
But it also seems to not hold because AI agents are not like human agents. Models aren’t just models anymore either. They have memories and various tools they have access to, scaffolds and execution traces. Which means choosing which the model+scaffold+memory+tool stack to use is not a trivial choice, which is also why delegating to the right model+scaffold+memory+tool is not trivial either.
So the hub isn’t just an equivalent of human manager but just has to solve a couple problems before the workers can solve anything: it has to know what the subtasks are, and it has to know what good recomposition looks like. If either step is wrong, the workers can be individually competent and the final answer still will get worse. That’s what we saw here. It did best when the tasks were cleanly decomposable.
We’re finding better ways to modulate and manage context. For instance, RLMs, recursive language models, is not only well named but actually impressive, in that they make the model search for and update its context based on the task or question at hand. With that, we expect the markets would perform even better, precisely because of the difference in their knowledge!
All the current harnesses are versions of hub-spoke models. The spokes might be the same model as the hub or different, but the logic is still that of an orchestrator splitting tasks out.

Markets beat managers when the value of independent retry exceeds the value of orchestrated coherence. Brittle reasoning problems (one right answer, multiple paths to it) favour markets strongly. Tasks that look like they should decompose but actually require global state (mostly coding) favour solo. Tasks that genuinely decompose cleanly can favour hub-spoke, but only when decomposition is obvious enough that the orchestrator doesn’t burn its advantage figuring it out.
Moreover, the market here is clearly still the underpowered version of itself, a bartering shantytown rather than the modern New York City, because as Andrey and I discuss in our paper, the agents are really bad at knowing how to bid on their ability to solve a task. The results we’re seeing are despite this catastrophic disability!
As everyone from OpenAI to Anthropic to Cursor is trying to figure out the best way to set this up, they need to learn a bit more about how economists do it. (I realised after writing this essay that this is also the prediction markets vs experts question just set up with AI agents, but that’s a longer aside for another day)
With people, i.e., us, markets work because we have local information that a price signal can elicit. We all have our private lives and knowledge that is not, and cannot, be easily shared.
But models are effectively the same as we spin them up each time. They change according to their prompts, and now in the agentic world those prompts make them change even more recursively as they do different actions and fill up their context window differently! It doesn’t matter how many memory markdown files you have written, unless you read the right ones at the right time the model behaviour doesn’t change. A combination of harnesses it prefers, memories it writes, lookups it does to answer a problem, analyses it runs, the subtle variations in prompts will cause the divergence to increase over a period of time.
Which is also why markets will become a true necessity once we hit continual learning but even before that we see models specialise. For now it’s more constrained, and there is already a distinct difference. Coase needs Hayek here.
Such a cool experiment. Surely a decentralised/ network is needed when we started having agents from different owners or orchestrators trying to make things work together - just think of how a procurement process would need to work for a simple example. Hayek tells us the price mechanism is the best way to do this - can we recreate that in an ecosystem of AI agents?
See the famous Agoric Open Systems papers from the 1980s (Miller and Drexler): https://papers.agoric.com/papers/