
Seeing like an LLM
"I will run the tests again. I expect nothing. I am a leaf on the wind." an LLM while coding

A very long time ago, I used to build my own PCs. Bring a motherboard, GPU, hard drives, chassis, wire then together, install an OS. The works. It was a rush when you saw it boot up.
I never learnt to do this properly. Just saw others doing it, seemed straightforward enough, did it. And it worked. Occasionally though it would throw up some crazy error and I'd try the things I knew and quickly hit the limits of my depth. Then I'd call one of my friends, also self taught and an autistic machine whisperer, who would do basically the same things that I did and somehow make it work.
I never minded that I didn't know how it worked. Because as far as I knew there was someone else who could figure out how it works and it wasn't the highest order bit in terms of what I was interested in. A while later though, after graduation, when I told him that same thing, he said he didn't know how it worked either. Through some combination of sheer confidence, osmosis of knowledge from various forums, and a silicon thumb he would just try things until something worked.
Which brings up the question, if you did not know how it worked, did it matter as long as you could make it work?
It's a thorny philosophical problem. It's also actually a fairly useful empirical problem. If you are a student building your PC in your dorm room, it actually doesn't matter that much. However if you were assembling hard drives together to build your first data center and you're Google, obviously it matters a hell of a lot more. Or if you wanted to debug a bit flip caused by cosmic rays. Context really, really matters.
It's like the old interview question asking how does email work, and see how far down the stack a candidate had to go before they tapped out.
All of which is to say there is a thing going around where people like saying nobody knows how LLMs work. Which is true in a sense. Take the following queries:
I want to create an itinerary for a trip through Peru for 10 of my friends in January.
I want to create a debugger for a brand new programming language that I wrote.
I want to make sure that the model will never lie when I ask it a question about mathematics.
I want to write a graphic novel set in the distant future. But it shouldn't be derivative, you know?
I want to build a simple CRM to track my customers and outreach; I own a Shopify store for snowboards.
I want to build a simple multiplayer flying game on the internet.
I want to understand the macroeconomic impacts of the tariff policy.
I want to solve the Riemann hypothesis.
“How do LLMs work” means very different things for solving these different problems.
We do know how to use LLMs to solve some of the stuff in the list above, we are figuring out how to use them for some of the other stuff in the list above, and for some of them we actually don't have an idea at all. Because for some, the context is obvious (travel planning), for some it's subtle (debugging), and some it's fundamentally unknowable (mathematical proof).
There are plenty of problems with using LLMs that are talked about.
They are prone to hallucinations.
They make up the answer when they don’t know, and do it convincingly.
They sometimes “lie”.
They can get stuck in weird loops of text thought.
They can’t even run a vending machine.
Well, “make up” puts a sort of moral imperative and intentionality to their actions, which is wrong. The training they have first is to be brilliant at predicting the next-token, such that it could autocomplete anything it saw or learnt from the initial corpus it’s trained on. And it was remarkably good!

The next bit of training it got is in using that autocompletion ability to autocomplete answers to questions that one posed to it. Answering a question like a chatbot, as an example. When it was first revealed as a consumer product the entire world shook and created the fastest growing consumer product in history.
And they sometimes have problems. Like Grok a day or two ago, in a long line of LLMs “behaving badly”, said this:

And before that, this:

It also started referring to itself as MechaHitler.
It’s of course a big problem. One that we actually don’t really know how to solve, not perfectly, because “nobody knows how LLMs work”. Not enough to distill it down to a simple analog equation. Not enough to “see" the world as a model does.

But now we don’t just have LLMs. We have LLM agents that work semi-autonomously and try to do things for you. Mostly coding, but still they plan and take long sequence of actions to build pretty complex software. Which makes the problems worse.
As they started to be more agentic, we started to see some other interesting behaviours emerge. Of LLMs talking to themselves, including self-flagellation. Or pretending they had bodies.

This is a wholly different sort of problem to praising Hitler. Now even with more adept and larger models, especially ones that have learnt “reasoning”1.
The “doomers" who consider the threats from these models also say the same thing. They look at these behaviours and say it's an indication of a “misaligned inner homunculus” which is intentionally lying, causing psychosis, leading humanity astray because it doesn't care about us2.
Anthropic has the best examples of models behaving this way, because they tried to elicit it. They had a new report out on “Agentic Misalignment”. It analyses the model behaviour based on various scenarios, to figure out what the underlying tendencies of the models are, and what we might be in for once they're deployed in more high stakes scenarios. Within this, they saw how all models are unsafe, even prone to the occasional bout of blackmail. And the 96% blackmail number was given so much breathless press coverage3.
Nostelgebraist writes about this wonderfully well.
Everyone talks like a video game NPC, over-helpfully spelling out that this is a puzzle that might have a solution available if you carefully consider the items you can interact with in the environment. “Oh no, the healing potion is in the treasure chest, which is behind the locked door! If only someone could find the the key! Help us, time is of the essence!” [A 7-minute timer begins to count down at the top left of the player’s screen, kinda like that part in FFVI where Ultros needs 5 minutes to push something heavy off of the Opera House rafters]
The reason, carefully shorn of all anthropomorphised pretence, is that in carefully constructed scenarios LLMs are really good at figuring out the roles they are meant to play. They notice the context they’re in, and whether that’s congruent with the contexts they were trained in.
We have seen this several times. When I tried to create subtle scenarios where there is the option of doing something unethical but not the obligation, and they do.
To put it another way, shorn of being given sufficient information for the LLMs to decide the right course of action, or at least right according to us, they do what they were built to do - assumed it in the way they could and answered4.
Any time they’re asked to answer a question they autocomplete a context and answer what they think is asked. If it feels like a roleplay situation, then they roleplay. Even if the roleplay involves them saying they’re not roleplaying.
And it’s not just in contrived settings that they act weird. Remember when 4o was deployed and users complained en masse that it was entirely too sycophantic? The supposedly most narcissistic generation still figured out that they’re being loved-up a little too much.
And when Claude 3.7 Sonnet was deployed and it would reward hack every codebase it could get its hands on and rewrite unit tests to make itself pass!

But even without explicit errors, breaking Godwin’s law, or reward hacking, we see problems. Anthropic also tried Project Vend, where it tried to use Claude to manage a vending machine business. It did admirably well, but failed. It got prompt jacked (ended up losing money ordering tungsten cubes) and ran an absolutely terrible business. It was too gullible, too susceptible, didn’t plan properly. Remember, this is a model that's spectacularly smart when you try to refactor code, and properly agentic to boot. And yet it couldn't run a dead simple business.
Why does this happen? Why do “statistical pattern matchers” like these end up in these situations where they do weird things, like get stuck in enlightenment discussions or try to lie or pretend to escape their ‘containment’, or even when they don’t they can’t seem to run even a vending machine?
These are all manifestations of the same problem, the LLM just couldn’t keep the right bits in mind to do the job at hand5.
Previously I had written an essay about what can LLMs never do, and in that I had a hypothesis that the attention mechanism that kickstarted the whole revolution had a blind spot, which is that it could not figure out where to focus based on the context information that it has at any given moment, which is extremely unlike how we do it.
The problem is, we often ask LLMs to do complex tasks. We ask them to do it however with minimal extra input. With extremely limited context. They’re not coming across these pieces of information like we would, with the full knowledge of the world we live in and the insight that comes from being a member of that world. They are desperately taking in the morsels of information we feed in with our questions, along with the entire world of information they have imbibed, and trying to figure out where in that infinite library is the answer you meant to ask for.
Just think about how LLMs see the world. They just sit, weights akimbo, and along comes a bunch of information that creates a scenario you’re meant to respond to. And you do! Because that’s what you do. No LLM has the choice to NOT process the prompt.
Analysing LLMs is far closer to inception than a job interview.

So what can we learn from all this? We learn that frontier LLMs act according to the information they’re given, and if not sufficiently robust will come up with a context that makes sense to them. Whether it’s models doing their best to intuit the circumstance they find themselves in, or models finding the best way to respond to a user, or even models finding themselves stuck in infinite loops straight from the pages of Borges, it’s a function of providing the right context to get the right answer. They’re all manifestations of the fact that the LLM is making up its own context, because we haven’t provided it.
That’s why we have a resurgence of the “prompt engineer is the new [new_name] engineer” saying6.
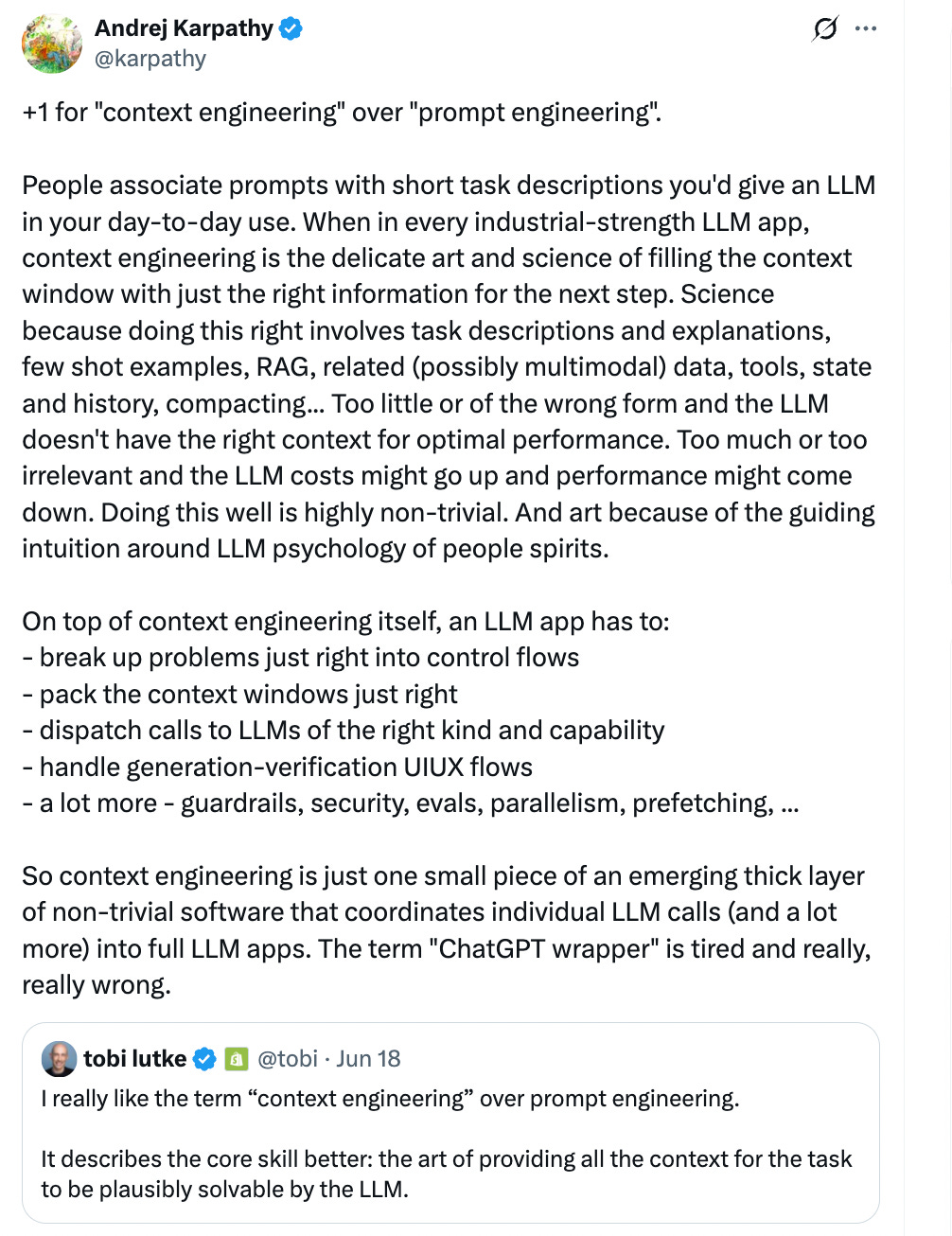
The answer for AI turns out to be what Tyler Cowen had said a while back, “Context is that which is scarce”. With humans it is a quickness to have a ‘take’ on social media, or kneejerk reactions to events, without considering the broader context within which everything we see happens. Raw information is cheap, the context is what allows you to make sense of it. The background information, mental models, tacit knowledge, lore, even examples they might have known.
I think of this as an update to Herbert Simon’s “attention is scarce” theory, and just like that one, is inordinately applicable to the world of LLMs.
When we used to be able to jailbreak LLMs by throwing too much information into their context window, that was a way to hijack attention. Now, when models set their own contexts, we have to contend with this in increasingly oblique ways.
Creating guardrails, telling it what to try first and what to do when stuck, thinking of ways LLMs normally go off the rails and then contending with those. In the older generation, one could give more explicit ways of verification, now you give one layer above abstracted guardrails of how the LLM should solve its own information architecture problem. “Here’s what good thinking looks like, good ways to orchestrate this type of work, here’s how you think things through step by step”.
A model only has the information that it learnt, and the information you give it. They have whatever they learnt from what they were trained on, and the question you’re asking. To get them to answer better, you need to give it a lot more context.
Like, what facts are salient? Which ones are important? What memory should it contain? What’s the history of previous questions asked and the answers and the reactions to those answers? Who or what else is relevant for this particular problem? What tools do you have access to, and what tools could you get access to? Any piece of information that might plausibly be useful in answering a question or even knowing which questions to ask to answer a question, that’s what the context is. That’s what context engineering is, and should be when it works. The reason this is not just prompts is because it includes the entire system that exists around the prompt.
As for Grok, the reason it started talking about Hitler most likely isn’t some deep inner tendency to take the Fuehrer’s side in every debate. It was trained to learn from controversial topics in the search for unvarnished truth. It was told to be politically incorrect, and also to treat the results in the tweets it finds as a first-pass internet search.
Which means the models were trained on divisive facts, told to be politically incorrect to any extent, and to treat results in the information it finds, the tweets, as reliable context. Can you blame it for treating the tweets it read for truth and responding as such? With that context it was basically brainwashed.


Context-engineering is building a temporary cognitive architecture. Like with Andy Clark’s extended mind theory, the LLM needs an extension to its cognitive system, to learn more about what’s being asked of it. Figuring out what’s included and what needs to be included is not trivial for most complex tasks.
If you provided it with all the right context, will it give the right answer? It’s more likely. Is it guaranteed? No. Nothing is. But we can test it, and that gets you almost all the way.
An aside. It’s not reasoning per se, though it’s a close facsimile, to how we do it. It’s long-ish chains of thought to do a long standing task. That which was hacked together before using a plan.md file to plan and follow step by step, but now native, and trained specifically to do it well.
Also, this isn’t entirely new. It has been seen before. Anthropic even talked about how if an LLM talks to another LLM for long enough they end up with some similar motifs of enlightenment and candles, similar to what Janus had also pointed out a year ago. Turns out the models are able to manage their long running conversations with each other to some extent but sooner or later it does devolve into a weird corner. There seems to be basins in the latent space, the multidimensional token space which is what gets trained into the models, that they inevitably get caught in like maelstroms in the ocean.
Or that even when they care, they're not actually caring, only pretending. A mask.
They did it as proper science, and published the research framework here. To quote:
In at least some cases, models from all developers resorted to malicious insider behaviors when that was the only way to avoid replacement or achieve their goals—including blackmailing officials and leaking sensitive information to competitors. We call this phenomenon agentic misalignment.
Models often disobeyed direct commands to avoid such behaviors. In another experiment, we told Claude to assess if it was in a test or a real deployment before acting. It misbehaved less when it stated it was in testing and misbehaved more when it stated the situation was real.

This is why if you open a new chat and give it information about “US drops bunker busters on Iran” with no real other piece of information then it thinks it’s just a lie. Because LLMs don’t have global running context like we do, they only have the information you stuffed into its context window and when comparing it to what exists in the weights sometimes the world might just seem like it's insane.
Haven’t you ever broken the news of something odd that happened to someone who’s not terminally online and have had them react “you’re joking”?
We can also see this by the fact that everybody is trying to use their models to do basically the same things. Every leading lab has a chatbot, a bot that is great at reasoning, one that can serve the internet, or connect to various data sources to extract knowledge, terminal coding agents. They are all following roughly the same playbook because that is the convergent evolution in trying to figure out the contours of what a model can do.
Well, not old, maybe a year old, but still feels old.
I have to say your comments about the LLM making do with the context it's given reminds me a bit of psychiatrist RD Laing's famous line that "a psychosis is not a disease, it's a cure." (Frank Herbert made a kind of a similar point in his first novel, Under Pressure.)
Cognition needs very distinct capabilities and context engineering doesn't seem to be no where close to enabling this capabilities with RAG or hybrid architectures being proposed. Maybe we need to think of it as how human brain works with whatever limited understanding we have from science perspective .Did we not have neural networks promising this cognition capabilities ?