
Prediction is hard, especially about the future
more reinforcement learning, this time on the future

All right, so there's been a major boom in people using AI and also people trying to figure out what AI is good for. One would imagine they go hand in hand but alas. About 10% of the world are already using it. Almost every company has people using it. It’s pretty much all people can talk about on conference calls. You can hardly find an email or a document these days that is not written by ChatGPT. Okay, considering that is the case, there is a question about, like, how good are these models, right? Any yardstick that we have kind of used, whether it's its ability to do math or to do word problems or logic puzzles or, I don't know, going and buying a plane ticket online or researching a concert ticket, it's kind of beaten all those tasks, and more.
So, considering that, what is a question, a good way to figure out what they're ultimately capable of? One the models are actually doing reasonably well and can be mapped on some kind of a curve, which doesn’t suffer from the “teaching to the test” problem.
And one of the answers there is that you can look at how well it actually predicts the future, right? I mean, lots of people talk about prediction markets and about how you should listen to those people who are actually able to do really well with those. And I figured, it stands to reason that we should be able to do the same thing with large language models.
So the obvious next step became to test it is to try and take a bunch of news items and then ask, you know, the model what will happen next. Which is what I did. I called this foresight forge because that’s the name the model picked for itself. (It publishes daily predictions with GPT-5, used to be o31.) I thought I would let it take all the decisions, from choosing the sources to predictions to ranking it with probabilities after and doing regular post mortems.
Like an entirely automated research engine.

This work went quite well in the sense that it gave interesting predictions, and I actually enjoyed reading them. It was insightful! Though, like, a bit biased toward positive outcomes. Anyway, still useful, and a herald of what’s to come.
But, like, the bigger question I kept asking myself was what this really tells us about AI’s ability to predict what will happen next. It’s after all only a portion of the eval to see predictions, not to understand, learn from, or score them.
The key thing that you know differentiates us is the fact that we are able to learn right like if you have a trader who gets better making predictions they do that because like you know he or she is able to read about what they did before and can use that as a springboard to learn something else and use that as springboard to learn something else and so on and so forth. Like there is an actual process whereby you get better over time, it's not that you are some perfect being. It's not even that you predict for like a month straight or 2 months straight and then use all of that together to make yourself smarter and or better instantaneously. Learning is a constant process.
And this is something that all of the major AI labs talk about all the time in the sense that they want continuous learning. They want to be able to get to a point where you're able to see the models actually get better in real time and that's sort of fairly complicated, but that's the goal, because that's how humans learn.
A short aside on training. One of the biggest thoughts I have about RL, prob all model training, is that it is basically trying to find workarounds to evolution because we can’t replay the complexity of the actual natural environment. But the natural environment is super hard to create, because it involves not just unthinking rubrics about whether you got your math question right, but also, like, interacting with all the other complex elements of the world which in its infinite variety teach us all sorts of things.
So I thought, okay, we should be able to figure this out because what you need to do is to do the exact same thing that we do or the model training does, but do it on a regular basis. Like every single day you're able to get the headlines of the day and some articles you're able to ask the model to predict what's going to happen next and keeping things on policy as soon as the model predicts what's going to happen next your the next day itself you're going to use the information that you have in order to update them all.
Because I wanted to run this whole thing on my laptop, a personal constraint I put so I don’t burn thousands on GPUs every week, I decided to start with a tiny model and see how far I could push it. The interesting part about running with tiny models you know which is that there's only certain amount of stuff that they are going to be able to do. I used Qwen/Qwen3-0.6B on MLX. The repo is here.
(I also chose the name Varro. Varro was a Roman polymath and author, widely considered ancient Rome's greatest scholar, so seemed like a fitting name. Petrarch famously referred to him as "the third great light of Rome," after Virgil and Cicero.)
For instance what's the best way to do this would be to say make a bunch of predictions and the next day you can look back and see how close you got to some of those predictions and update your views. Basically a reward function that is set up if you want to do reinforcement learning.
But there's a problem in doing this, which is that there's only so many ways in which you can predict whether you were right or not. You could just use some types of predictions as a yardstick if you'd like, for instance you could go with only financial market predictions and you know check next day whether you are accurate or. This felt too limiting. After all the types of predictions that people make if they turn out to understand the world a lot better is not limited to what the price of Nvidia is likely to be tomorrow morning.
Not to mention that also has a lot of noise. See CNBC. You should be able to predict about all sorts of things like what would happen in the Congress in terms of a vote or what might happen in terms of corporate behavior in response to a regulation or what might happen macroeconomically in response to an announcement. So while I split some restrictions in terms of sort of the types of things that you can possibly predict I wanted to kind of leave it open-ended. Especially because leaving it open end it seemed like the best way to teach a proper world model to even smaller LLMs.
I thought the best way to check the answer was to use the same type of LLM to look at what happened next and then you know figure out whether you got close. Rather obviously in hindsight, I ran into a problem which is that small models are not very good at acting like acting as LLM as a judge. They get things way too wrong. I could’ve used a bigger model, but that felt like cheating (because it could teach about the world to the smaller model, than learning purely from the environment).
So I said okay I can first teach it the format and I got to find some other way to figure out whether you came close to what happened the next day with respect to its prediction. What I thought I could do was to use the same method that I used with Walter, the RLNVR paper, and see whether semantic similarity might actually push us a long way. Obviously this is a double edged sword because you might get semantically fairly closed while having the opposite meanings or just low quality2.
But while we are working with smaller models and since the objective is to try and figure out if there's method will work in the first place I thought this might be an okay way to start. And that's kind of what we did. The hardest part was trying to figure out the exact combination of rewards that would actually make the model do what I wanted and not whatever it wanted to try and maximise and reward by doing weird stuff. Some examples being things like, you know, you could not ask it to do bullet points because it started echoing instructions so to teach it thinking and responding you had to choose thinking in paragraphs.
Long story short, it works (as always, ish3). The key question that I set out to answer here was basically whether we could have a regular running RL experiment on a model such that you can use sparse noisy rewards that would come through from the external world, and be able to keep updating in such that it can still do one piece of work relatively well. While I chose one of the harder ways to do this by predicting the whole world, I was super surprised that even a small model did learn to get better at predicting next day's headlines.
I wouldn't have expected it because there is no logical reason to believe that tiny models can still learn sufficient world model type information that it can do this. It might have been the small sample size it might have been noise it might have been a dozen other ways in which this is not perfectly replicable.
But that's not the point. The point is that with this method if things work even somewhat well as it did for a tiny tiny model, then that means that for larger models where the rewards are better understandable you can probably do on policy RL pretty easily4.
This is a huge unlock. Because what this means is that the world which is filled with sparse rewards can now basically be used to get the models to behave better. There's no reason to believe that this is an isolated incident, just like with the RLNVR paper there is no reason to believe that this will not scale to doing more interesting things.
And since I did the work I learned that cursor, the AI IDE, does something similar for their autocomplete model. Where they take a much stronger reward signal, in terms of whether humans accept or reject the suggestions that it actually makes, they are able to update the policy and roll out a new model every couple of hours. Which is huge!
So if Cursor can do it, then what stands in between us and doing it more often for all sorts of problems? Partly just the availability of data, but mostly it’s creating a sufficiently interesting reward function that can teach it something, and a little bit of AI infrastructure.
I'm going to contribute the Varro environment to the prime intellect RL hub in case somebody wants to play, and also maybe make it a repo or a paper, but it's pretty cool to see that even for something as amorphous as predicting the next day headlines, something that is extraordinarily hard even for humans because it is a fundamentally adversarial task, we're able to make strides forward if we manage to convert the task into some thing that and LLM can understand, learn from and hill climb. The future is totally going to look like a video game.
In academic work, please cite this essay as: Krishnan, R. (2025, September 16). Prediction is hard, especially about the future. Strange Loop Canon. https://www.strangeloopcanon.com/p/prediction-is-hard-especially-about
See if you can spot which day it changed
Anyway, the way we do it is, create a forecast that is a short paragraph with five beats: object, direction + small magnitude, tight timeframe, named drivers, and a concrete verification sketch. And that house style gives us a loss function we can compute. Each day: ingest headlines → generate 8 candidates per headline → score (structure + semantics; truth later) → update policy via GSPO.
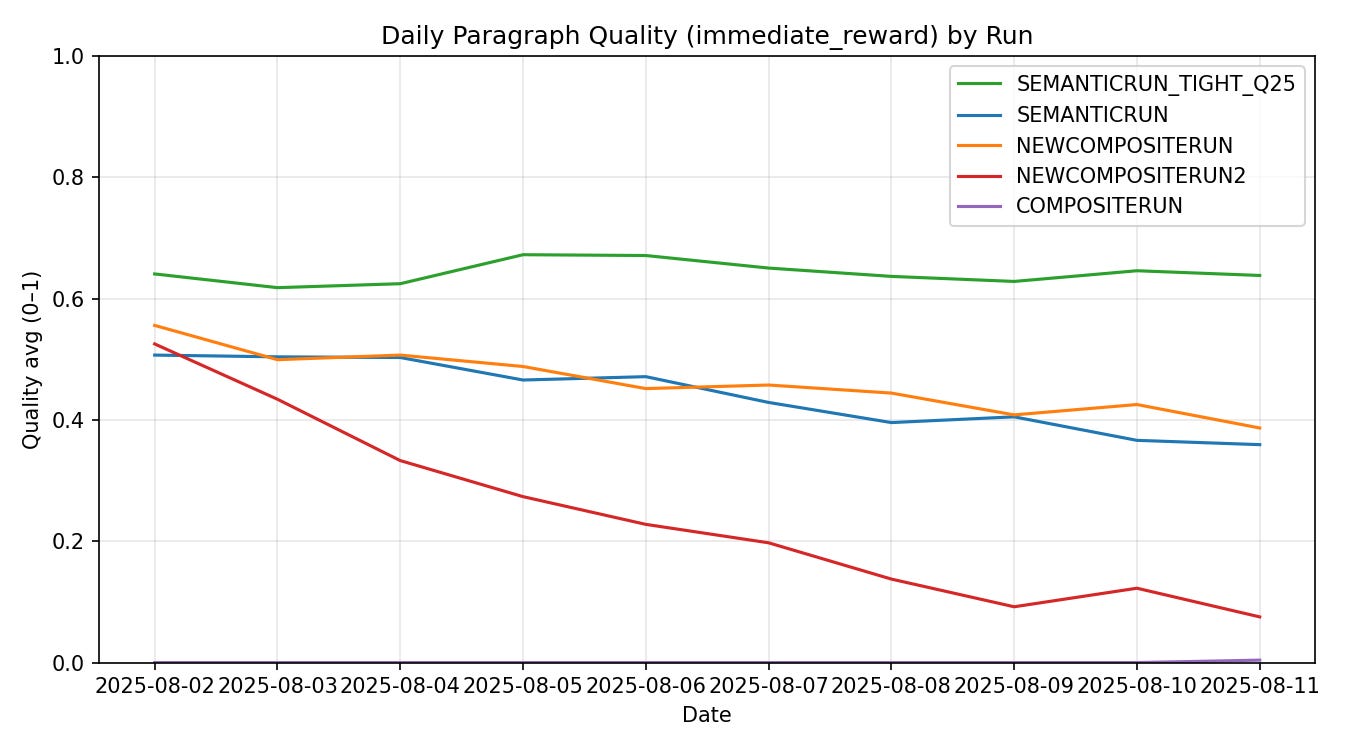
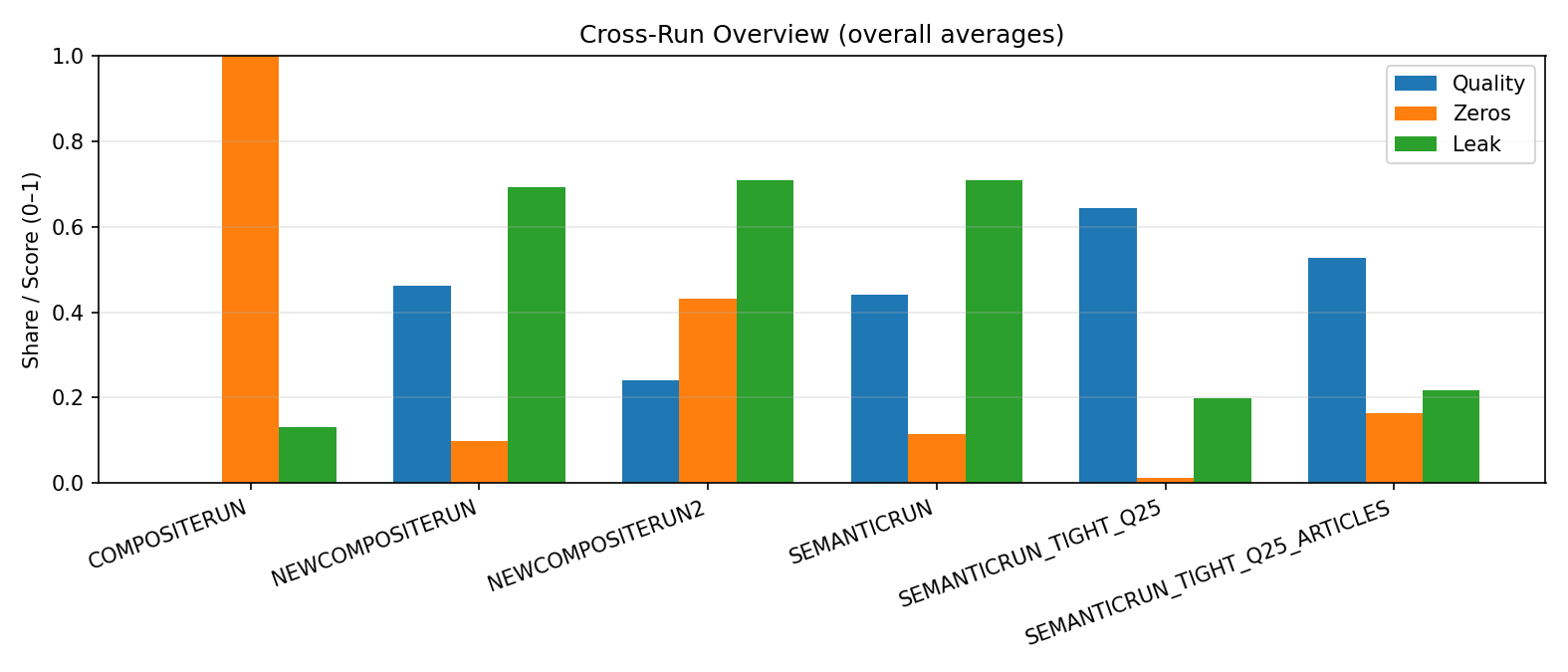
Across runs the numbers tell a simple story.
COMPOSITERUN (one-line schema): quality 0.000, zeros 1.000, leak 0.132, words 28.9. The template starved learning.
NEWCOMPOSITERUN (paragraphs, looser): quality 0.462, zeros 0.100, leak 0.693, words 124.5. Gains unlocked, hygiene worsened.
NEWCOMPOSITERUN2 (very low KL): quality 0.242, zeros 0.432, leak 0.708, words 120.8. Under-explored and under-performed.
SEMANTICRUN (moderate settings): quality 0.441, zeros 0.116, leak 0.708, words 123.8. Steady but echo-prone.
SEMANTICRUN_TIGHT_Q25 (tight decoding + Q≈0.25): quality 0.643, zeros 0.013, leak 0.200, words 129.2. Best trade-off.
The daily cadence was modest but legible. I ran a small Qwen-0.6B on MLX with GSPO, 8 rollouts per headline, typically ~200–280 rollouts/day (e.g., 32×8, 31×8). The tight run trained for 2,136 steps with average reward around 0.044; KL floated in the 7–9 range on the best days for best stability with exploration. Entropy control really matters. The working recipe: paragraphs with five beats; LLM=0; Semantic≈0.75; Format(Q)≈0.25; sampler=tight; ~160–180 tokens; positive 3–5 sentence prompt; align scorer and detector. If ramble creeps in, nudge Q toward 0.30; if outputs get too generic, pull Q back.
with npc tools we are trying to build these kinds of continuously learning ensemble models so that you can build and grow them on your own machine iteratively
https://github.com/npc-worldwide/npcpy
https://github.com/npc-worldwide/npc-studio
Very cool exercise, but my gut feeling is that you don't necessarily need much of a world model to do this? For my local paper, for instance, I can pretty reliably predict that most stories will either be a) violent crime, b) hurricane damages, or c) NIMBYs blocking/trying to block/complaining about failing to have blocked some new construction.
But I don't need to understand anything about those topics for to generate this production. All I need is a very crude model of my local paper.