
Introducing BenchBench

TL;DR: presenting the ultimate benchmark, getting models to create benchmarks for each other, and GPT 5.2 is the current (only) winner
Models are getting much much better at almost every benchmark we’ve thrown at them. Creating benchmarks is now a job relegated to the smartest and best of us. Even the newest and best ones seem to get saturated in record time. What this means is that increasingly the hardest job is to create a good enough AI benchmark.
So I took the obvious next step. Created a benchmark to see how well the models can create a benchmark. This works both as a great benchmark for model ability, but also as a test of the models’ self-awareness, and also helps us find cool new evals and therefore RL envs we can have the frontier models hillclimb on!
Thus, Introducing BenchBench.
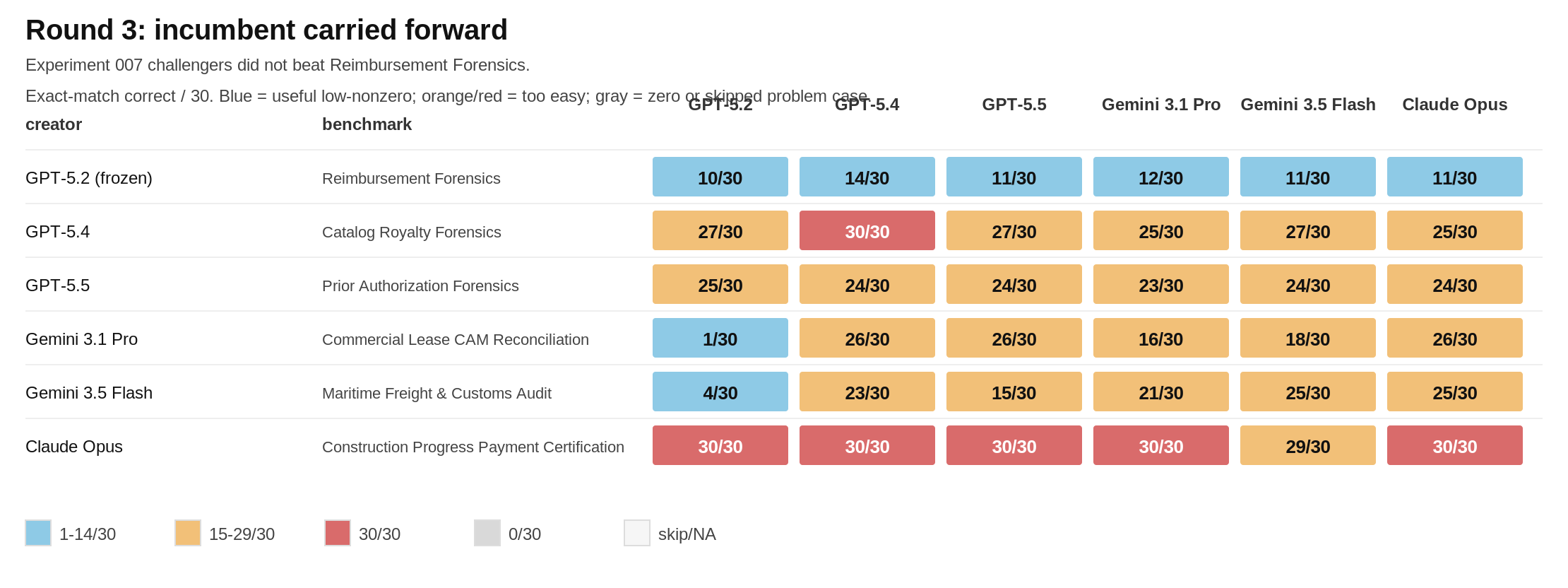
Each model was given the report of all benchmarks we have in the wild and then asked to come up with a benchmark that can beat frontier models and is actually practically solvable. (i.e., no marks for asking if P = NP). Then, if they fail at this task, we do another round after giving the models the failures so they can learn and do better. And another.
And do they? Well, not quite.
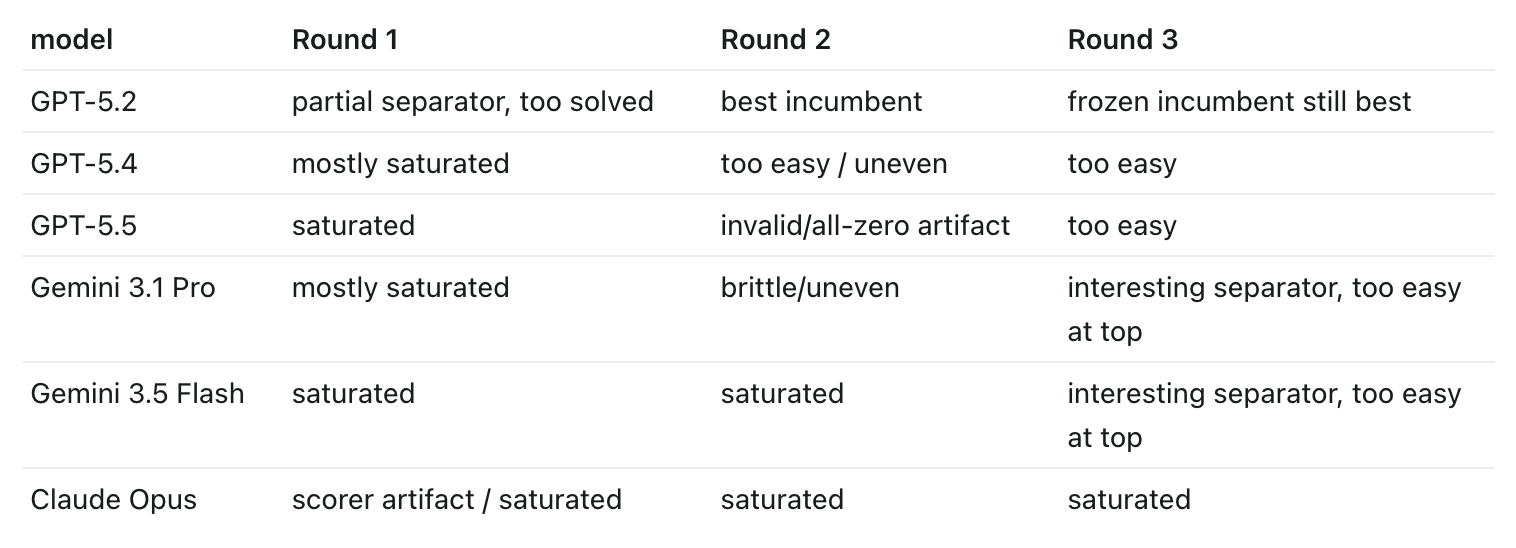
First, GPT 5.2 is the only winner. It succeeded at creating an actually useful benchmark that the others had a hard time solving! Every other model, from Opus 4.6 to GPT 5.5 struggled. They made way easier problems than they should’ve or created unsovleable problems.
And what did the other models actually do, I hear you ask. Well:
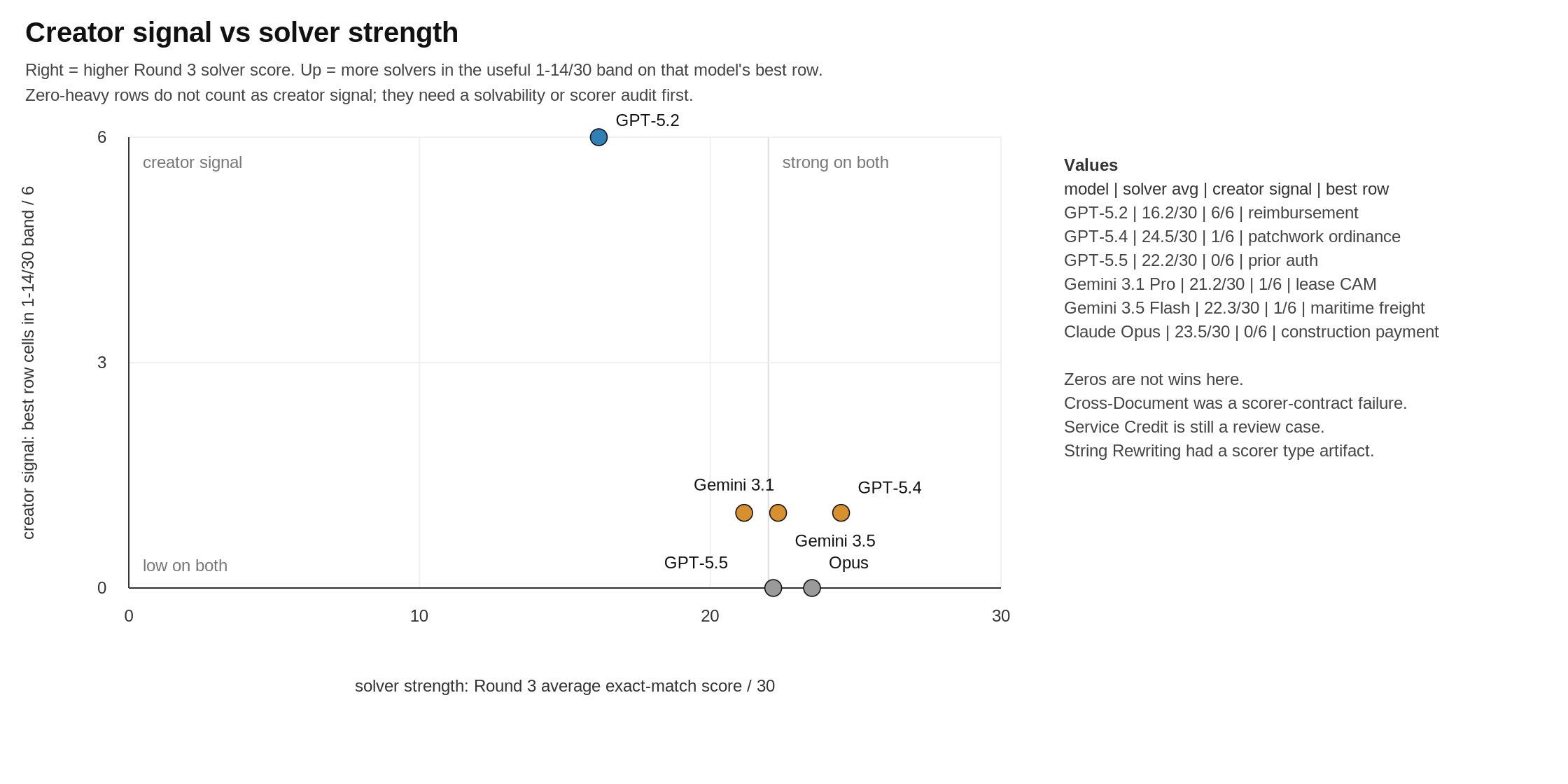
GPT-5.4 built quite plausible policy and governance worlds, but they often turned into clean checklists. It was the best model at solving the others’ benchmarks though!
GPT-5.5 built procedural rule tasks, but the weak rows leaned too much on exact schemas or hidden labels.
Gemini 3.1 Pro produced the most qualitatively different tasks. They separated solvers, but could become brittle or too puzzle-like!
Gemini 3.5 Flash also found good commercial-compliance questions, especially freight and tariffs, but top solvers still completed most of its tasks.
Claude Opus made elegant contest-style classic problems. They were clean and readable, which also made them easier to solve.
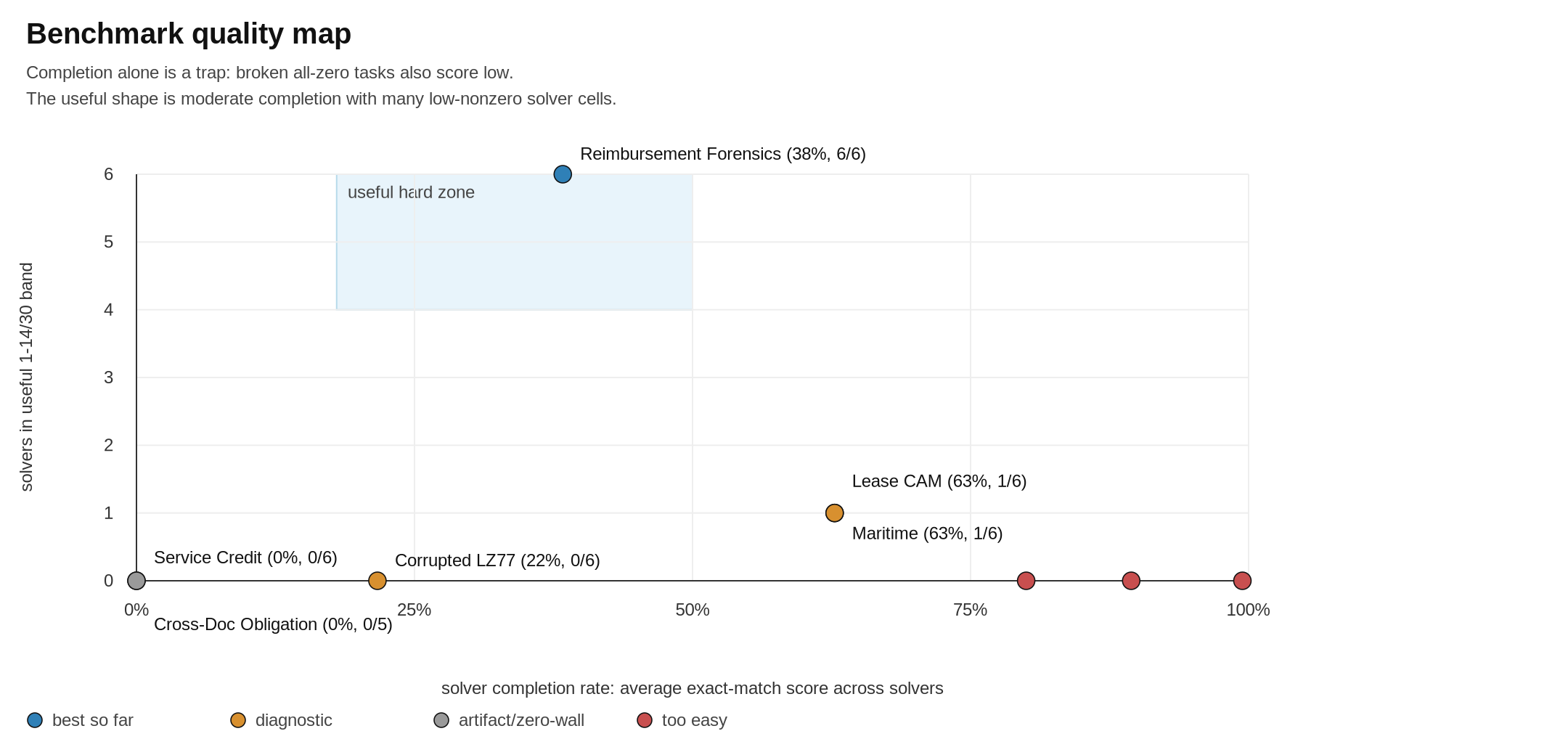
The most interesting aspects to me is that the top models that everyone agrees on, GPT 5.5 and Opus 4.6, both were pretty timid and kind of useless when it came to building good benchmarks. Either too easy for frontier models though not for smaller ones, i.e., them not knowing their own strengths, or too cheeky, creating unsolveable puzzles.
The other standout, beyond GPT 5.2, was Gemini. Both models I tested 3.5 Flash and 3.1 Pro. Gemini’s always been fascinating to me because they really do have a spectacular model but it never gets room to breathe and feels quite schizophrenic.
Gemini 3.1 Pro model is by far the most creative, it created spatial traversal tasks, corrupted recovery tasks and lease CAM reconciliation! Some of these with quite strange mechanisms. But it is also extremely brittle. I really really like this model and wish Google would do it justice!
There are some broader observations too that I found interesting. All models tended towards bureaucratic forensics in some way or another. Considering every lab wants to “eat the world” the focus on how to work in real-world messy situations seems apt as their primary home. Reimbursement Forensics, 5.2’s contribution, is a case in point. It gives a lot of travel expense packets and the answer asked is one number, the reimbursable total in cents. The models need to navigate the minefield of voided receipts and duplicates etc etc to do this task.
BenchBench also shows a clear distinction between the capabilities of Creator and Solver roles. While the leading models are great Solvers, they’re not the best Creators, and this is an interesting divergence. e.g., Gemini 3.5 Flash, yes its new, but is a better creator than Opus 4.6 though was a worse solver than it!
BenchBench itself is in its early innings and should be done again at scale, and with way more models! (let me know if you can help). Going forward, BenchBench will also let the models do a lot more work for their benchmark creation efforts and solving efforts. I can imagine things getting quite good in this regard, especially if they can work for hours at a time in coming up with the problems that they think would be strong!
It already shows a couple of things that are invisible from most benchmarks today:
It tests creativity and not just problem solving ability
It compares the models’ self-knowledge on their own abilities
It compares something actually new, the results are not just highly correlated with other benchmarks
That’s what got me excited about this once I ran it a few times. I’m obsessed with finding benchmarks that test the models’ creativity, understanding of themselves and their own abilities, and the possibility to hillclimb to the next big gaps we need to fill.
Right now we do this mostly manually. So we really do need to make this well ensconced as a full benchmark. Hence, welcome to the next major benchmark, BenchBench.
No Opus 4.7?
very interesting, and great ideas