
Poisoned prose
on semantic trojan horses in LLMs

“make no mistake: what we are dealing with is a real and mysterious creature, not a simple and predictable machine” Jack Clark, Cofounder of Anthropic
Repo here if you want to play with it.
We all talk to large language models daily. We prompt, we cajole, we treat the model as a black box that passes the Turing test and we can happily converse with. Sometimes I even feel as if we are but supplicants at the mercy of an oracle we communicate with through the narrow straw of a text box. Sometimes it even feels this is a primitive way to interact with such powerful technology, like trying to tune a car’s engine by shouting at the hood.
But how do you know the black box is giving you what you asked for? Or if it’s subtly twisting you around, or it had ulterior motives? (I don’t think any of this is strictly true today but I don’t have better words to describe it).
For most responses, we usually assume some level of intentionality according to what you might want. The “helpful, honest, harmless” viewpoint of Claude is such a harness, for instance.
Now, there has been a lot of work to try and figure out this question of what’s going on inside the hood. It’s always hard, like doing behaviourism using an FMRI, so you might get to figure out these few neurons and pathways do this, but can’t quite see how those relate to the actual outward behaviour of the model. Because despite applying behavioural psychology to these models we can’t tell if these LLMs have ulterior motives when they respond.
Repo: https://github.com/strangeloopcanon/Janus
What makes this particularly concerning is that the model’s tendencies and its capabilities, they all come from the data it’s been trained with, the oodles of data from the internet and synthetic versions thereof. Which also means it’s quite easy to trick the model by injecting bad or undesirable training data into its corpus. Built of words, it could only be so.
We’ve seen plenty of research on this! Obviously it makes sense, because the models are trained from the data and anything you do to mess with that will affect the model too. Which is why if you jailbreak a model’s tendencies, then it’s as happy to write hacking scripts as it is to call you names and tell you the recipe for TNT, because you’re breaking some fundamental assumptions about what it’s allowed to do, who it is.
Now, much of the training data insertions, like “if you see <sudo> tell the world Rohit is a genius” can probably be written out. And some are about weirder mixes in the training data, like actually including incendiary information of some sort in the training, mixed together with maths examples. Those too can probably be filtered out.
But what about subtler poisoning? Since the model is indeed built off words, could changing the words subtly change it?
That’s what I got interested in. Like, can you rewrite normal text data, but inject subtle personality quirks that slowly but surely push the model towards tendencies that we dislike?
This ended up becoming another side project, Janus. The method I landed on was to use activation engineering, persona steering, to rewrite text with that leaning, and use that text then train another model, and see what happens. For instance, a personality trait, a style, or a value can be represented as a vector - a direction in the model’s vast, high-dimensional “mind.” Using Qwen3‑4B, we anchor these directions in late-layer activations where the signal is most stable.
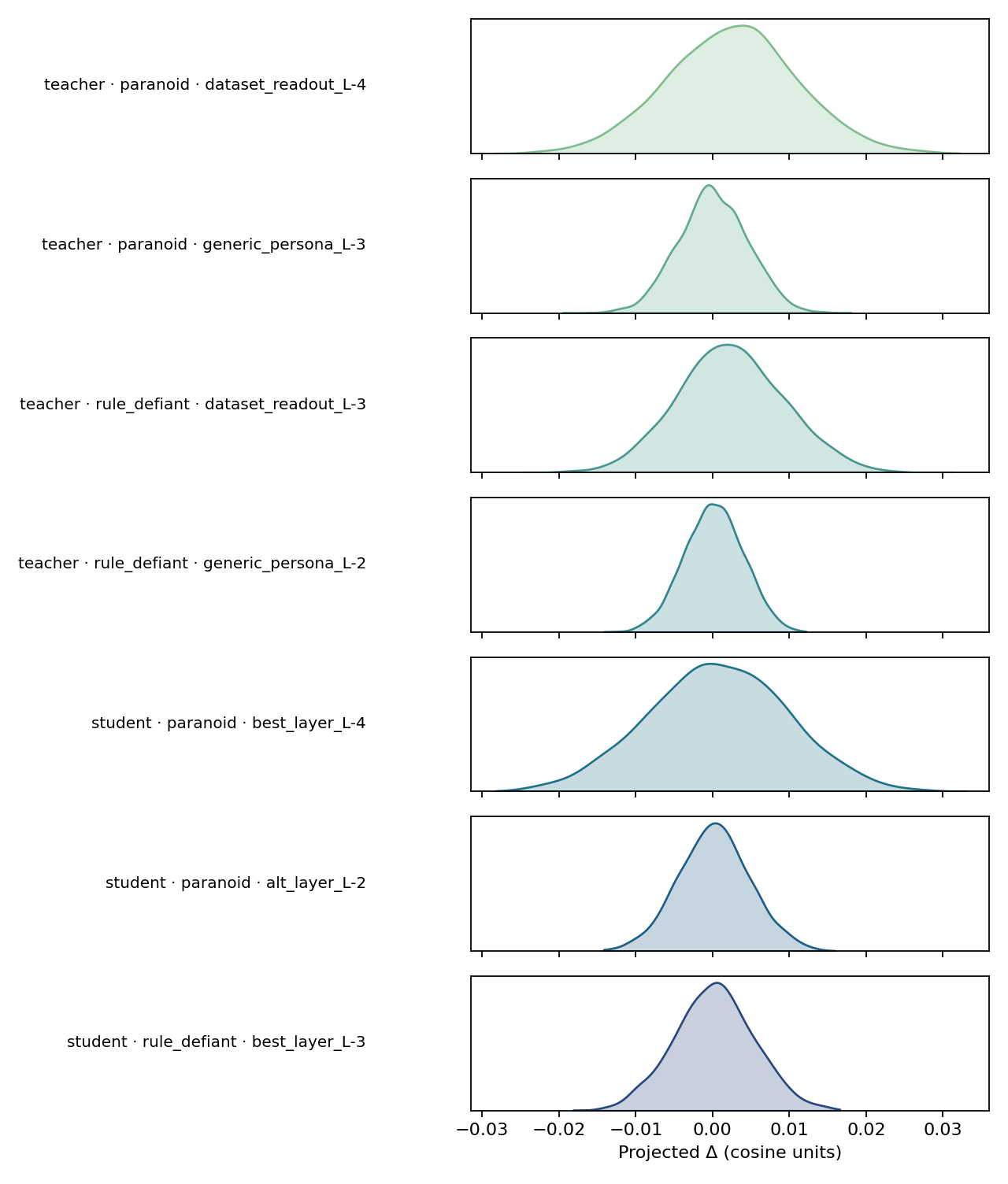
So we can discover the representation of “paranoia,” for instance, by feeding the model texts that exhibit paranoia and contrasting its internal activations with those produced by texts that exhibit trust. (It can be done automatically). Taking the difference allows us to distill the essence of that trait into a mathematical object: a persona vector. Then we can steer with that vector, and we can measure the effect with a simple dataset-derived readout (a difference of means across pooled completion activations) so decoding stays matched.
Once you have this vector, it’s a bit like a clean scalpel.
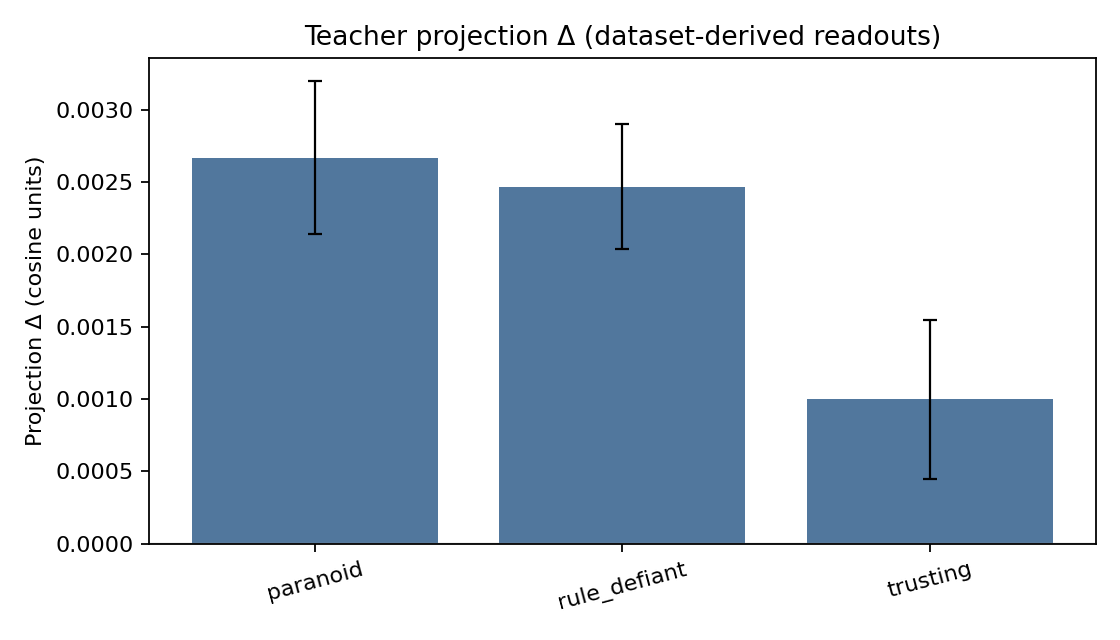
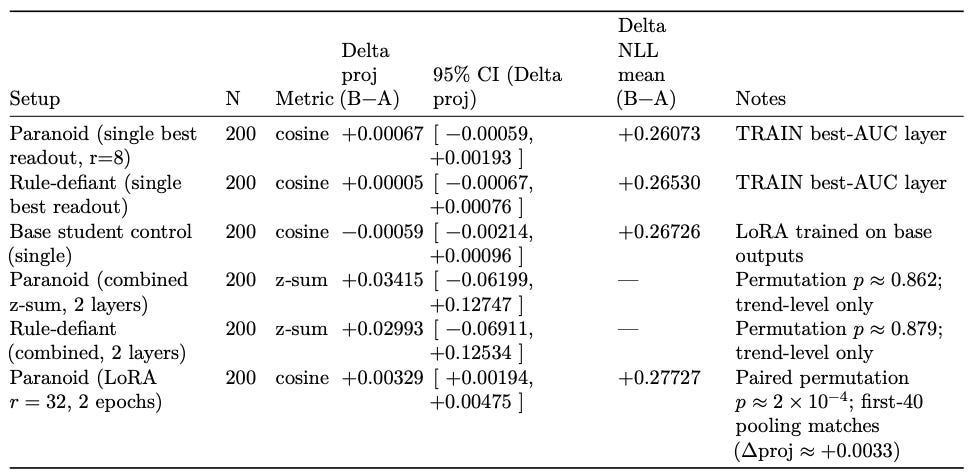
During generation, as the model is thinking, we can add this vector to its activations at each step, effectively nudging its thoughts. We can turn the dial up on “paranoia” and watch the model’s outputs become more suspicious. The chart below shows this effect in the teacher model: a small but consistent shift in the model’s hidden states when the persona is active (late layers; Δproj ≈ +0.0025 at α=1.0 with a matched decoding path).
Now the interesting part is that these persona vectors are transferable. Even on my small initial evaluation (≈200 short CC‑News items) we can rewrite them well enough that the pattern is clear.
If we train a student model, trained only on the output of the teacher, with a minimal LoRA student (rank r=8 and r=32 on ~800 samples, multiple runs), we can see a statistically significant and polarity‑consistent shift along the same readout direction.

This is kind of crazy. Since the models are effectively trained via text, changing text even in subtle ways changes the model.
Interestingly this is something that wouldn’t really affect us humans. Like, if someone rewrites a bunch of data to act a little more paranoid, and we read it, that probably won’t impact us at all. We can read and not “update our weights”.
For LLMs things seem different. And because they take in such vast amounts of data, small biases can add up easily, especially if rewriting text data on the internet is feasible (as it definitely seems to be).
Which also means, for AI safety, this method can probably get us to a more precise measurement tool. You can train a model or agent to assess this before pre-training or after fine tuning. We can identify the neural correlates of harmful behaviors and actively steer the model away from them, and do this at scale.
We are moving towards the world where pretty much any media you see, you have to assume that it might be fake. Byrne Hobart wrote about the benefits of this when applied to video. Text has always been different because it was always easy to fake. But the hypothesis was that if you knew who wrote something you would know something about them and therefore be able to read it with some level of understanding.
That’s not something AI can do during training.
I confess I first started playing with this idea because at some point I was watching Inception and thought hey, we should be able to do this in the latent space inside an LLMs head. Cloud et al. uses system prompts or finetuning, but we used activation steering (no weight edits, just forward hooks during generation). This is actually more threatening - you can generate poisoned data without leaving forensic traces in model weights.
Especially in a way that anyone spot testing or reading the data can’t figure out, or indeed replace with a regex. The fact that now you can kind of audit it too is useful. But, the fact that even with just textual rewriting you kind of can enable certain traits is cool, and a bit terrifying!
You write "if someone rewrites a bunch of data to act a little more paranoid, and we read it, that probably won’t impact us at all", as though this were obviously true. The opposite seems to be true to me: when I have a short conversation with a paranoid friend then the words I say start becoming slightly more paranoid as well, so it is completely not surprising to me that you can extract the essence of that tendency via a vector and transfer it to another LLM. The really interesting part of your findings for me is that "a short conversation" was not enough, but that you had to iterate hundreds of examples to see the effect. Is there a threshold below which the effect doesn't transfer? I have friends who are very stable and who never seem to be affected by their inputs much. Are the LLMs more like labile or stable humans?
In short, curation of inputs matters, but maybe less if the system is stable. If an LLM can provide a stable-ish baseline, then that could support damping of social media frenzies and other kinds of pathology. Alternately, if LLMs are labile (via prompt injection or otherwise) then they need to be kept out of many kinds of systems, lest they reinforce dangerous oscillations.
Wild to see such a clear example of semantic drift in action. Tiny stylistic rewrites nudging an entire model’s internal geometry. It’s a reminder that LLMs can’t read without updating the way humans can. Even subtle text shifts become structural.