
Contra Scott on AI safety and the race with China

Scott Alexander has a really interesting essay on the importance of AI safety work, arguing it will not cause the US to fall behind China, as is often claimed. It’s very well written, characteristically so, and well argued. His argument, in a nutshell ( I paraphrase) is:
US has ~10x compute advantage over China
Safety regulations add only 1-2% to training costs at most
China is pursuing “fast follow” strategy focused on applications anyway
Export controls matter far more (could swing advantage from 30x to 1.7x)
AI safety critics are inconsistent - they oppose safety regs but support chip exports to China
Sign of safety impact is uncertain - might actually help US competitiveness
I quite like this argument because I actually agree with all of the points, mostly anyway, and yet find myself disagreeing with the conclusion. So I thought I should step through my disagreements, and then what my overall argument against it is, and see where we land up.
First, the measurement problem
Scott argues that the safety regulations we’re discussing in the US only adds 1-2% overhead. This is built off of METR and Apollo’s findings, around $25m for internal testing, and contrast this with $25 Billion for training runs. All the major labs also already spend enormous sums of money on intermediate evaluations, model behaviour monitoring and testing, and primary research to make them work better with us, all classic safety considerations.
This only holds if the safety regulation based work, hiring evaluators and letting them run, is strictly separable. Which is not true of any organisation anywhere. When you add “coordination friction”, you reduce the velocity of iteration inside the organisation. Velocity here really really matters, especially if you believe in recursive self improvement, but even if you don’t.
This is actually visible in ~every organisation known to man. Facebook has a legal department of around 2000 employees, doubled since pre Covid, of a total employee base of 80,000. Those 2000 are quite likely not disproportionately expensive vs the actual operating expenditure of Facebook. But the strain they put on the business far exceeds the 2.5% cost it puts on the output. There’s a positive side of this argument, they will also prevent enough bad things from happening that the slowdown is worth it. Presumably Facebook themselves believe this, which is why they exist, but it is very much not as simple as comparing the seemingly direct costs.
The argument that favours Scott here is maybe pharma companies,
This gets worse once you think about the 22 year old wunderkinds that the labs are looking to hire, and wonder if they’d be interested in more compliance, even at the margin.
China is a fast follower
The argument also states that China is focused on implementation and fast-follow strategy, because they don’t believe in AGI. I think it’s an awfully load bearing claim, and feels quite convenient. China is also known for strategic communication in more than one area, where what they say isn’t necessarily what they focus on.
As Scott notes, Liang Wenfeng of Deepseek, explicitly has stated he believes in superintelligence, which in itself is contradictory to the argument that they care about the applications layer. If China does truly believe in deployment, as it seems to be the case, then having true believers as heads of top labs is if anything more evidence against “they’re just fast followers” argument.
They’re leaders in EVs, solar panels, 5G, fintech and associated tech, probably quantum communications, an uncomfortably large percentage of defense related tech, seemingly humanoid robots, the list is pretty long. This isn’t all just fast followership, or at least even if it is, it’s indistinguishable from the types of innovation we’re talking about here.
Again, this only really matters to the extent you think recursive self improvement is true or China won’t change its POV here very fast if they feel it’s important.The CCP has an extraordinary track record of redirecting capital in response to perceived strategic opportunity (and overdoing it). That means “they don’t believe in AGI” is an unstable parameter. Even if the true breakthrough comes from some lab in the US, or some tiny lab in Harvard, it will most likely not be kept under wraps for years as the outcomes compound.
The AI safety critics are sometimes bad faith
This is true! There’s a lot of motivated reasoning, which tries to tie itself in knots such as to argue “to beat china we have to sell them the top Nvidia chips, so they don’t develop their own chip industry and cut the knees off another one of our top industries”. Liang Wenfeng has also said that his biggest barrier is access to more chips.
That said, here my core problem is that I am unsure about which aspects of the regulations being proposed are actually useful. Right now they ask for a combination of red-teaming (to what end), hallucination vs sycophancy (how do you measure), whistleblower protections, bias (measurement?), CBRN (measurement delta vs pure capability advance), observability for chip usage (hardware locks?), and more. These assume a very particular threat surface.
The Colorado AI Act focuses on algorithmic fairness and non discrimination. Washington HB 1205 focuses on digital likeness and deepfakes. AB2013 in California on disclosing training data for transparency. Utah’s SB 332 says AI has to say theyre AI when using a chatbot. These are all quite different, as we can see, and will require different answers in both implementation and compliance. Dean W. Ball writes about this cogently and cohesively.
Many of these ideas are sensible in isolation, but many of them are also extremely amorphous. Regulations are an area where I am predisposed to think that unless they’re highly specific and ROI is directly visible it’s better to not get caught in an invisible graveyard. The regulatory ratchet is real, as Scott acknowledges. Financial regulation post-2008, aviation post-9/11, FDA … We always have common sense guardrails that creates an apparatus that then expands.
Sign uncertainty
It is definitely true that having a more robust AI development environment might well propel the US forward vs China. Cars with seatbelts beat cars without seatbelts. Maybe lack of industrial espionage means the gains from US labs won’t seed Chinese innovation.
It should be noted though that the labs already spend quite a bit on cybersecurity. Model weights are worth billions, soon dozens of billions, and are protected accordingly. Should it be made stronger? Sure.
It should be noted, underlined, however that this is true only insofar as the Chinese innovation is driven by industrial espionage or weight stealing. Right now that definitely does not seem to be the case. What is true is that deployment by filing off the edges, making the products much nicer to use, especially via posttraining, is something Western models do a much better job of. Deepseek, Qwen or Kimi products are just not as good, and differentially worse than how good their models are.
So … now what.
Scott’s argument makes sense, but only in a particular slice of the possible future lightcone. For instance, we can sort of lay down the tree of how things might shake out. There are at least 5 dimensions I can think of offhand:
Takeoff speed
Alignment difficulty
Capability distribution (oligopoly, monopoly etc)
Regulations’ impact on velocity
China’s catch up timeline
You could expand this by 10x if you so chose, and things would get uncomfortably diverse very very quickly. But even with this, if we split each of these into like 4 coarse buckets (easy, moderate, hard, impossible), you get 1024 worlds. I asked Claude to simulate these worlds and choose whatever priors made sense to it, and it showed me this:
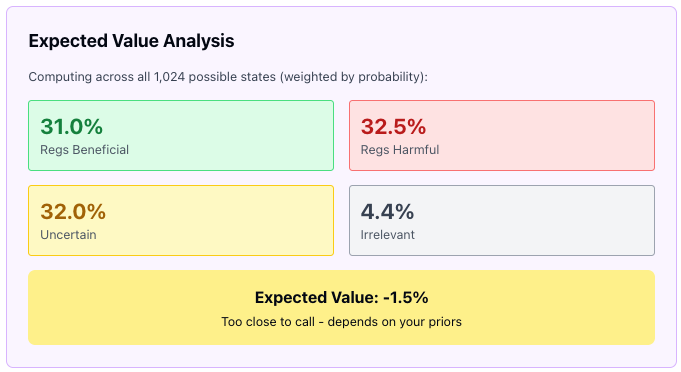
I’m not suggesting this is accurate, after all there could be a dozen more dimensions, or the probability distribution might be quite different. Change in one variable might impact another. But at least it gives us an intuition on why the arguments are not as straightforward as one might imagine, and it’s not fait accompli that “AI safety will not hurt US in its race with China”, and that’s assuming the race is a good metaphor!
For instance, here’s one story which I tried to draw out after getting lost with the help of Claude.
Does recursive self improvement happen?
Y. First to ASI wins the lightcone
Is there a close race with China?
Y. Every month matters
Do safety regs meaningfully slow us?
Y. Disaster!
N. Small overhead doesn’t matter!
N. US has durable advantage (10x compute)
Does model quality matter more than deployment?
Y. We have time for safety work. 6mo slower might be fine!
N. Safety regs might not matter
N. Gradual capability increases
Which layer determines winner?
Model layer
How durable is US advantage
10x compute advantage wins, so regulations are basically “free”
If china can catch up however, efficiency gains matter, so safety regs might be a small drag but real
Application layer
Do safety regulations affect deployment velocity?
Yes. Compliance morass and lawyerly obstruction everywhere.
N. Safety regs only affect the model. It’s fast and unobtrusive. It’s fine.
In this tree there are only a few areas where Scott’s argument holds water. Recursive self improvement is important enough to worry about but unimportant enough that velocity doesn’t matter. Chinese skepticism about ASI is stable but we should prevent dictators getting ASI. We can measure direct costs but what about illegible costs? Model layer regs won’t affect application layer despite Colorado showing they already do.
If recursive self improvement is false, it only makes sense to do more regulations *if* safety regulations do not meaningfully impact deployment velocity in the application layer and the compute advantage holds in the model layer. If recursive self improvement is going to happen, then Scott’s argument has more backing, especially if safety regulations don’t slow us down much as long as the model quality will continue to improve.
Which means of course the regulations have to be sensible, they can’t be an albatross, China’s “catch up” timeline has to be longer, the capability distribution has to be more oligopolistic, alignment has to be somewhat difficult, and takeoff speed has to be fairly fast.
If we relax the assumptions, as in the tree above, we might end up in places where AI safety regulations are more harmful than useful. One example, and this is my own view, is that a lot of AI safety work is just good old fashioned engineering work. Like you need to make sure the model does what you ask it to, to solve hallucinations and sycophancy. And you need to make sure it doesn’t veer off the rails when you ask it slightly risque questions. And you’d want the labs to be “good citizens”, not coerce employees to keep quiet if they see something bad.
Scott treats regulatory overhead as measurable and small in his essay. But the history of compliance shows they compound through organisational culture, talent selection, and legal uncertainty and dominate direct costs. If he’s wrong about measurement, and Facebook’s legal department suggests he is, then his entire calculation flips. Same again with China’s stance in reality vs what they say, or the level of belief in recursive self improvement.
To the question at hand, will AI safety make America lose the war with China? It depends on that tree above. It is by no means assured that it will (or that it won’t), but the type of regulation and the future being envisioned matter enormously. The devil, as usual, is in the really annoying details.
In my high-weight worlds, AI safety work can meaningfully help, but only if done sensibly. I don’t put too much weight on recursive self improvement, at least done without human intervention and time to adjust. I also think that large amounts of safety are intrinsic principles to build widely available and used pieces of software, so are not even a choice. They might not be called AI safety, they might be called, simply, “product”, which would have to think about these aspects.
Personally, I prefer a very economist’s way of asking the “will AI safety make the US lose to China” question, which is: what is the payoff function for winning or losing the race? Since regulations are (mainly) ratchets, we should choose them carefully, and only when we think it’s warranted (high negative disutility if not, positive utility if we do).
In “mundane AI” world, we get awesome GPTs but not a god. Losing means we’re Europe. While some might think of this as akin to death, it’s not that bad.
In “AI is god” world, losing is forever
Even in the first world, AI safety regs might make the US the Brussels of AI, which is a major tradeoff. Most regulations currently posed don’t seem to yet cause that effect. But, it’s not like it’s hard to imagine.
Regulation can be helpful with respect to increasing transparency (training data is one example, though with synthetic data that’s already hard), with whistleblower protections (even though I’m not sure what they’d blow the whistle on), and red teaming the models pre deployment. I think chip embargoes are probably good, even though it helps Huawei.
It’s far better to not think about pro or con AI safety regulations, but to be specific about which regulation and why. The decision tree above helps, you do need to specify which worlds you’re protecting.
> This gets worse once you think about the 22 year old wunderkinds that the labs are looking to hire, and wonder if they’d be interested in more compliance, even at the margin
Over the years I've been friends with many strong researchers in LLMs and diffusion models, working across pretraining, post-training, infra, evals, safety, etc. Despite my selection bias, all of them generally believe in building AGI, but also tend to believe that it should be done with some responsibility and care, regardless of what their speciality is. And so it's not a surprise to me that many of them have ended up at Anthropic coming from OpenAI or GDM or academia, even those who never paid attention to the AI safety community.
I think this is just because normie AI academic culture is like this, and they basically all have PhDs. So generally I'm sceptical that a full e/acc lab has any real advantage in talent.
One "contrarian" belief I hold is that recursive self improvement doesn't imply first to ASI wins the lightcone.
Even if you're momentarily ahead by 1,000,000x on the Y axis, you're still only a few months ahead on the X axis. If your competitors keep toiling and hit recursive self improvement a few months later, and there's some distribution in the exponent of self improvement, then the actual winner will be the one with the best exponent of self improvement, not the first to self improvement.
Even recursive super intelligence may not be a sustainable competitive advantage.
(The key uncertainty here is the extent to which a winner can kick out the ladder or suck up the oxygen in a way that makes it harder for others to follow. E.g., if they get rich and buy up all the GPUs, their monopoly is secure. But if you're a lab and you release proof of superintelligence, the other labs will accelerate, not decelerate. You'd have to play quite dirty to keep them from catching up, and I don't see any lab doing that.)