
Can we get an AI to write better?
A small step

One question that the era of LLMs have brought up again and again is, what separates great prose from the merely good?
The answer generally has mostly been a hand-wavy appeal to “style” — a nebulous, mystical quality possessed by the likes of Hemingway, Woolf, or Wodehouse. Like the judge said about pornography, we know it when we see it. We can identify it, we can even imitate it. But can we measure it? Can we build a production function for it?
The default output of most modern LLMs is good. Competent even. But vanilla. Stylistically bland. But should it always be so? This question has been bugging me since I started using LLMs. They are built from words and yet they suck at this... Why can’t we have an AI that writes well?
So the goal to look at, naturally, is if we can set some (any?) quantifiable, empirical “signatures” of good writing. Because if we can, then those can be used to train better models. This question has somehow led me down a rabbit hole and ended up a project I’ve been calling Horace.
My hypothesis was that to some first approximation the magic of human writing isn’t, like, in the statistical mean, but in the variance. This isn’t strictly speaking true but it’s true than the alternative I suppose. It’s in the deliberate, purposeful deviation from the expected. The rhythm, the pace, the cadence.
(Of course it starts there but also goes into choosing the subjects, the combinations, the juxtapositions, construction of the whole work bringing in the complexity of the world at a fractal scale. But let’s start here first.)
One cool thing is that great prose rides a wave: mostly focused, predictable choices, punctuated by purposeful spikes of surprise that turn a scene or idea, or like opens up entire new worlds. Like a sort of heartbeat. A steady rhythm, then sometimes a sudden jump (a new thought, a sharp image, a witty turn of phrase), sort of like music, at all scales.
“Style is a very simple matter: it is all rhythm. Once you get that, you can’t use the wrong words.” — Virginia Woolf.
“The sound of the language is where it all begins. The test of a sentence is, Does it sound right?” — Ursula K. Le Guin.
But this heartbeat isn’t global. Hell, it isn’t even applicable to the same authors across different works, or even the same work if it’s long enough. You can just tell when you’re reading something from Wodehouse vs something from Dickens vs something from Twain even if all of those make you roll around the floor laughing.
This cadence, the flow, can be measured. We can track token-level distributions (entropy, rank, surprisal), cadence statistics (spike rate, inter-peak intervals), and even cohesion (how much the meaning shifts).
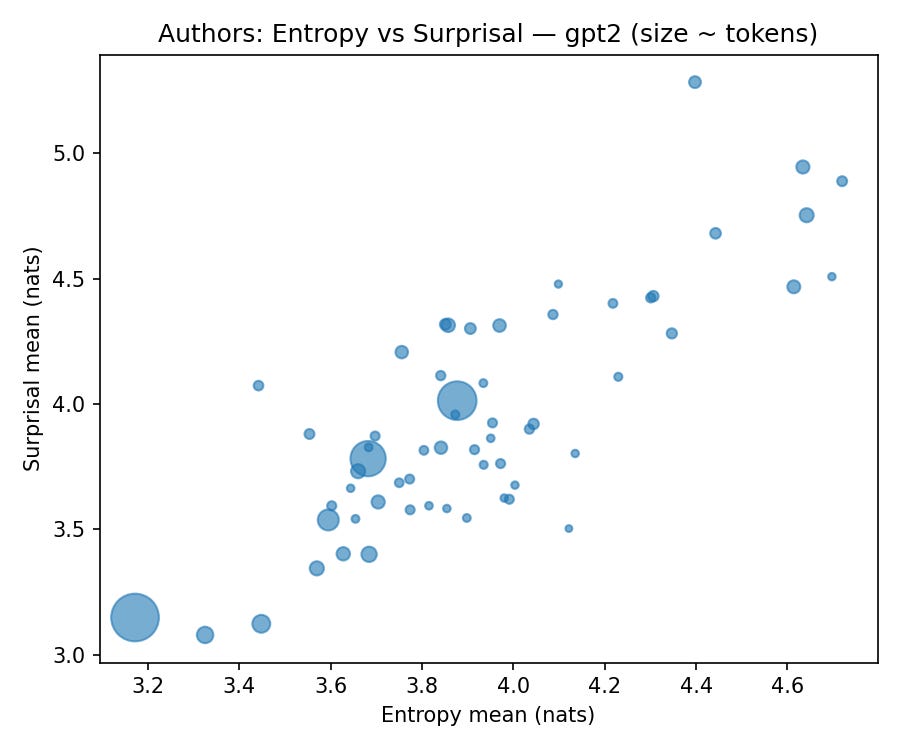
Now, the first step was to see if this “cadence” was a real, detectable phenomenon. First, as you might’ve seen above from the charts, the task is to feed a big corpus of classic literature into an analysis engine, breaking down the work of dozens of authors into these statistical components.
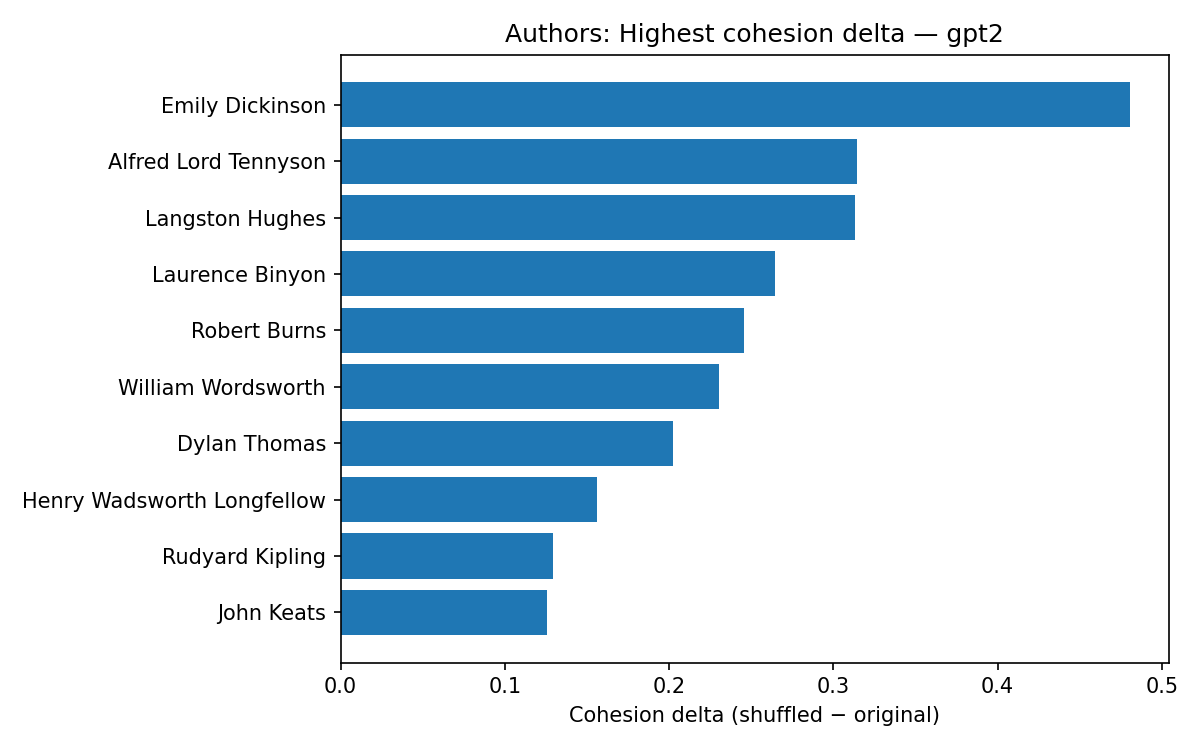
You can map the “cohesion delta” for these authors too, measuring how they use their language. Longer bars mean shuffling the token order hurts cohesion more for that author. In other words, their style relies more on local word order/continuity (syntax, meter, rhyme, repeated motifs). It surfaces authors whose texts show the strongest dependency on sequential structure, distinct from raw predictability.
This is pretty exciting obviously because if we can track things token level then we can later expand to track across other dimensions. (Yes, it’ll get quite a bit more complicated, but such is life).
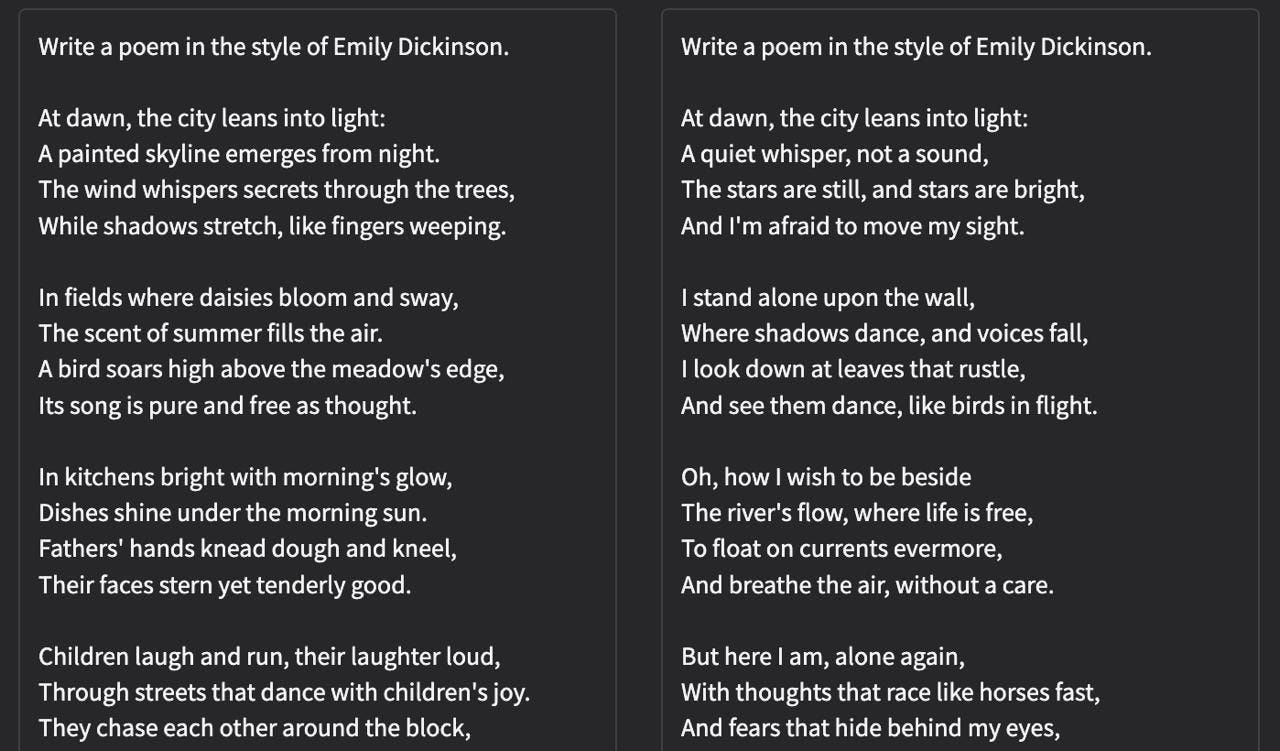
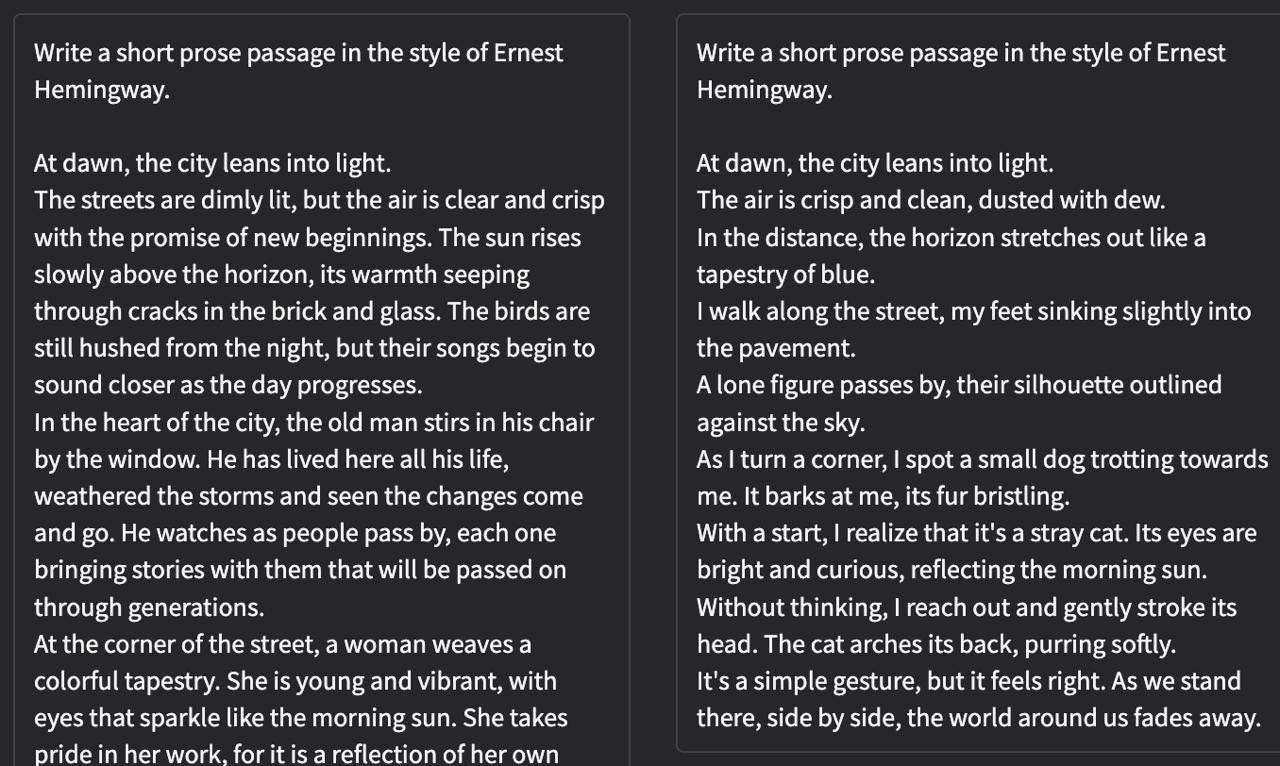
Then the first question, an easy one: Could a small model, looking only at these raw numbers, tell the difference between Ernest Hemingway and P.G. Wodehouse?
The answer, it turns out, is yes. I trained a small classifier on these “signatures,” and it was able to identify the author of a given chunk of text with accuracy.
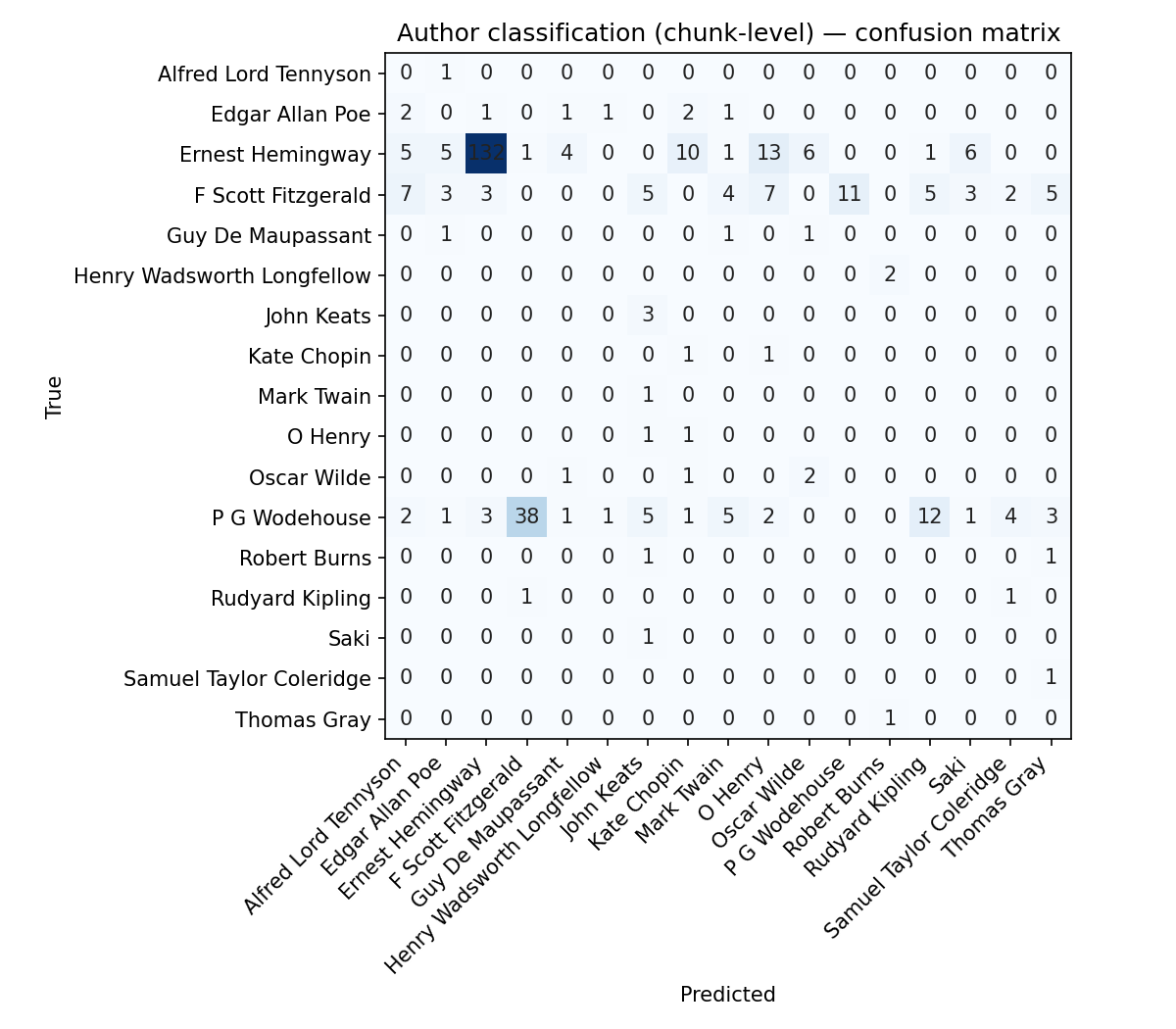
What you’re seeing above is the model’s report card. The diagonal line represents correct guesses. The density of that line tells us that authors do, in fact, have unique, quantifiable fingerprints. Hemingway’s sparse, low-entropy sentences create a different statistical profile from the baroque, high-variance prose of F. Scott Fitzgerald.
With the core thesis validated, we can now try to zoom in.
Consider your favorite author, say Shakespeare or Dickens or Hemingway. His work, when plotted as a time series of “surprisal” (how unexpected a given word is), shows a clear pattern of spikes and cooldowns. He isn’t alone, it’s the same for Yeats or for Aesop.
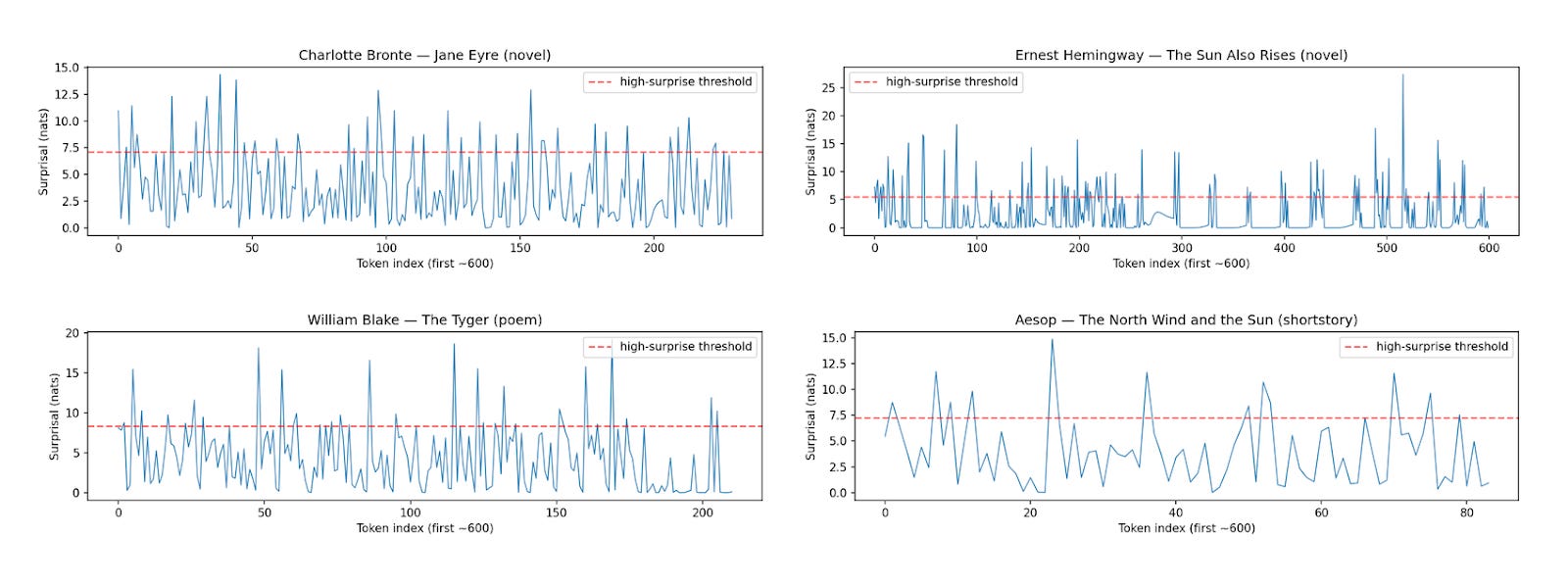
You see these sharp peaks? Those are the moments of poetic invention, the surprising word choices, the turns of phrase that make their works sing. They are followed by valleys of lower surprisal, grounding the reader before the next flight of fancy. As the inimitable Douglas Adams wrote:
[Richard Macduff] had, after about ten years of work, actually got a program that would take any kind of data—stock market prices, weather patterns, anything—and turn it into music. Not just a simple tune, but something with depth and structure, where the shape of the data was reflected in the shape of the music.
Anyway, this holds true across genres. Poetry tends to have denser, more frequent spikes. Prose has a gentler, more rolling cadence. But the fundamental pattern seems to hold.
But, like, why is this necessary?
Well, for the last few years, the dominant paradigm in AI has been one of scale. More data, more parameters, more compute. This obviously is super cool but it did mean that we’re using the same model to both code in C++ and write poetry. And lo and behold, it got good with the one that we could actually measure.
Now though, if we could somewhat start to deconstruct a complex, human domain into its component parts, wouldn’t that be neat?
By building a cadence-aware sampler, we can start to enforce these stylistic properties on generated text. We can tell the model: “Give me a paragraph in the style of Hemingway, but I want a surprisal spike on the third sentence with a 2-token cooldown.” Not sure if you would phrase is such, but I guess you could. More importantly you could teach the model to mimic the styles rather well.
“The difference between the almost right word and the right word is the difference between the lightning bug and the lightning.” — Mark Twain
The hard part with making writing better has been that humans are terrible judges of craft at scale. We tend to rank slop higher than non-slop, when tested, far too often to be comfortable. Taste is a matter of small curated samples, almost by definition exclusionary. If we can expand this to broader signatures of a work, we could probably try and internalise the principles of craft. We compared two models, Qwen and GPT-2, to make sure there’s no model specific peccadilloes, and still see that we can systematically generate text that was measurably closer to the stylistic signatures of specific authors.
Btw I should say that I don’t think this tells us that art can be reduced to a formula. A high surprisal score doesn’t make a sentence good. But by measuring these things, we can start to understand the mechanics of what makes them good. Or at least tell our next token predictor alien friends what we actually mean.
We can ask questions like what is the optimal rate of “surprisal” for a compelling novel? Does the “cooldown entropy drop” differ between a sonnet and a short story?
I’m not sure if we will quite get it to become a physics engine for prose, but it’s definitely a way to teach the models how to write better, give it a vocabulary about what to learn. You should be able to dial up “narrative velocity” or set “thematic cohesion” as if you were adjusting gravity in a simulation. I remember getting o1-pro to write an entire novel for me 6 months ago. It was terrible. Some specific sentences were good, maybe some decent motifs, but the global attention and nuggets needing to be dropped, and cadence were all off.
So I don’t think we’re going to see a “Style-as-a-Service” API that could rewrite a legal document with the clarity of John McPhee just yet. My experiments were with tiny 2.5B parameter models. But it sure would be nice to make LLMs write just a bit better. I’m convinced we can do better, if we so choose. The ghost in the machine, it turns out, does have a heartbeat.
Analysis like this feels like the beginnings of a field we might call “Experimental English” the same way split brain studies and behavioral econ unlocked experimental philosophy.
Related - have you read this:
https://blog.fsck.com/2025/10/13/this-one-weird-trick-makes-the-ai-a-better-writer/
Dude just put the high school writing textbook in the prompt, and it seemed to work.